Experiment parameters
The parameters that can be set in the categorization, extraction and thesaurus experiments are described below.
Training docs
The selection of the documents to use to train the model in the Training docs tab is the first step of categorization and extraction experiments that generate models. Its parameters are:
-
Training documents selection policy
This parameter applies to all the categorization and extraction experiments that generate a model.
It determines which documents from the training set are used for training. Possible values are:- Only validated documents (strict): only annotated documents that have also been validated will be used to train the model.
- Only validated or annotated documents (strict): only documents that are annotated or validated will be used to train the model.
- Prefer validated documents: in case of sub-sampling, validated documents will be preferred over non-validated documents.
- Prefer annotated documents: in case of sub-sampling, annotated documents will be preferred over non-annotated documents.
- Random selection: the documents used to train the model will be randomly selected from the library.
-
Enable subsampling using random selection strategy
This parameter applies to ML categorization experiments and to Auto-ML extraction experiments.
When turned on, only a randomly selected subset of the training library is used to train the model. The Subsampling max documents parameter (see below) determines the size of the subset.
-
Subsampling max documents
This is a sub-parameter of Enable subsampling using random selection strategy (see above). It determines the size of the subset.
The following parameters apply to ML extraction experiments and affect the areas of text around annotations (windows) that are considered in the training process.
-
Ignore non-annotated areas
When turned on, for non-validated documents, the only portions of text used to train the models are those around the annotations. The size of the area around annotations is determined by the Annotated area window size parameter (see below). For validated documents, instead, all the text is considered.
-
Annotated area window size
This is a sub-parameter of Ignore non-annotated areas (see above).
It's the size of the area around annotations to consider for training. It's expressed in sentences before and after the sentence containing the annotation, so for example value 2 means the area includes two sentences before and two sentences after.
-
Enable Negative Sub-sampling
It's alternative to Ignore non-annotated areas (see above).
When turned on, the training algorithm smartly chooses some non-annotated areas around annotations and excludes them from training in order to reduce noise.
Model type
Use the Model type tab to select a model type for your experiment. This tab is available for these experiments:
- Auto-ML Extraction
- Online-ML Categorization
- Auto-ML Categorization
- Online-ML Extraction
More information about model types in the dedicated pages.
Problem definition
Problem definition is a step of ML categorization experiments. Its parameters are described in the Problem definition tab and are:
-
Enable strict "single label" mode
When turned on, the model predicts at most one category for each document. When off, the model can detect any number of categories.
-
Enable strict "Sub document categorization" compatibility mode (only with Auto-ML Categorization)
When turned on, the generated model can predict categories for sub-documents, that are portions of the input document.
Platform authoring application does not handle the concept of sub-document and so, during an experiment, the model is trained with entire documents, annotated with the expected categories, and predicts categories for entire test library documents. For this reason, when you wave a sub-document categorization use case, it is necessary that the original documents are broken into sub-documents using an external tool and then sub-documents are imported as "normal" documents in the training and test libraries. This way you train and test the model on documents that are, indeed, chunks of larger source documents.
Once published and inserted in a workflow, however, the model can effectively manage sub-documents provided that:
- The input to the model block contains the text of the whole document plus the information (boundaries) that identifies sub-documents inside it.
- The type of boundaries is specified as a configuration parameters of the model block.
Under these conditions the model makes predictions for sub-documents and each output category is accompanied by the boundaries of the portion of the input document which identify the sub-document the category refers to.
Feature space
Feature space parameters affect ML categorization and extraction experiments and determine which features of the text are used to train the model. They are described in the Feature space tab.
In Auto ML experiments, Platform can automatically decide the features to use. This behavior is activated when the Automatic features selection option is turned on.
Available features that can be used or not are:
| Feature | Description | Experiment type |
|---|---|---|
| Alpha Numeric words | Words consisting of both letters and digits | Extraction |
| Alphabetic words | Words consisting only of letters | Extraction |
| Collocations | Combined words, the combination has its own meaning (e.g. credit card or take a risk) | Extraction |
| Decimal number words | Words representing decimal numbers | Extraction |
| Digit words | Words consisting only of digits | Extraction |
| Entities | Named entities like people, places and organizations | Categorization and extraction |
| Knowledge Graph relations | Knowledge graph ascending concepts, along ISA-type relationships, of the concept corresponding to text words (e.g. dentist is a medical specialist, which is a doctor, which is a professional) | Categorization and extraction |
| Knowledge Label | Main lemma of the concept which, inside the knowledge graph, in an ISA relation, is the parent of the concept corresponding to the text word (e.g. if the text word is moratorium, its parent concept's label is legal action ) | Categorization |
| Known Concepts | Knowledge graph concepts (syncons) for text words that are well known proper nouns (e.g. World Cup, United States) | Extraction |
| Logic dependencies | Syntactic relationships between text words (e.g. subject-verb-object) | Extraction |
| Main lemma | Base forms (lemmas) of the most important words of the text | Categorization |
| Main Syncons | Knowledge graph concepts (syncons) of the most important words of the text | Categorization |
| Main Topics | Knowledge graph topics the text is primarily about | Categorization |
| Mixed case words | Words consisting of both uppercase and lowercase letters | Extraction |
| Numeric words | Words that represent numbers | Extraction |
| Phrases | Phrases, i.e. one or more words that form a meaningful grammatical unit | Extraction |
| Sub-words | Parts of a word like morphemes, stems and roots | Categorization |
| Syncon Topics | The topics that in the knowledge graph are attributed to the concepts (syncon) corresponding to the text words | Categorization |
| Syncons | Knowledge graph concepts (syncon) corresponding to text words | Categorization and extraction |
| Title case words | Capitalized words | Extraction |
| Upper case word | Words consisting only of uppercase letters | Extraction |
| Use word embeddings | Static word embeddings | Categorization |
| Word base form (Lemma) | Base form (lemma) of text words (e.g. run for running and ran) | Categorization and extraction |
| Word base form stem | Stem of text words (e.g. intern for international) | Categorization |
| Word form | Text word exactly as written in the text | Categorization |
| Word Part-of-Speech | Part-of-speech of a word (e.g. noun, verb, adjective) | Extraction |
Other feature space parameters are:
-
For ML categorization and Online ML-Extraction experiments:
- Max features: the maximum number of text features to use to train the model. Value 0 means all available features.
-
For categorization experiments:
- Maximum N for N-grams: the N to compute N-grams for stem and keywords features. All the N-Grams up to N will be computed, thus value 1 means that only Unigrams will be computed while with 3 Unigrams, Bigrams and Trigrams will be used.
- Min DF: the minimum number of documents in which a feature must appear to be considered for training.
- Max DF: the maximum percentage of documents in which a feature can appear to be considered for training.
-
For Online ML-Extraction experiments:
- Min WF: the minimum number of windows (areas around annotations) per document in which a feature must appear in order to be considered for training.
- Max WF: the maximum percentage of windows per document in which a feature can appear to be considered for training.
Hyperparameters
Hyperparameters apply to ML categorization and extraction experiments. They are described in the Hyperparameters tab.
-
Alpha regularizer
Applies to these categorization model types:
Regularization parameter, smoothing factor on term counts. Large values increase the regularization.
-
C parameter: penalty for misclassifications
Applies to these categorization model types:
The C parameter is a regularization (or generalization) parameter for training data.
It is a number and it is used to prevent over-fitting and under-fitting.
If you have a big training set and you consider it representative, the parameter value should be small to increase the regularization and force the model to be tailored on training data. On the contrary, if you have a small training set, which may not be representative, it is better to select a large value to avoid the possible errors related to a strong regularization. -
Class weight
Applies to these categorization model types:
Regularization parameter to balance categories. Possible values are:
- Balanced
- None
If one category is preponderant over all the others in the training set, balancing categories prevent unbalanced predictions for less represented classes. If the training model is highly representative, balancing makes the model a little less performing. If, on the other hand, the training model is not very representative and balancing is not enabled, model performance is poor.
-
CRF c1 regularization coefficient
Applies to the CRF extraction model type.
Regularization coefficient, if set to greater than 0, it enables the Orthant-Wise Limited-memory QuasiNewton (OWL-QN) method as L1 (alpha) regularization value.
-
CRF c2 regularization coefficient
Applies to the CRF extraction model type.
Regularization coefficient. If a values is set, it enables the L2 (lambda) regularization value of the l2sgd and lbfgs training algorithms.
-
CRF Forced use of all possible states
Applies to the CRF extraction model type.
When enabled, the algorithm generates state features for all the combinations of attributes and labels and that possibly don't occur in the training data (negative state features). This may improve labeling accuracy but slow down the training process. -
CRF Forced use of all possible transitions
Applies to the CRF extraction model type.
When enabled, the algorithm generates transition features for all the possible pairs of labels, even if they don't occur in training data (negative transition features). -
Custom kernel type to be applied
Applies to the Custom kernel SVM categorization model type.
It's the kernel function to use to represent features. -
Degree of polynomial for polynomial kernel
Applies to the Custom Kernel SVM categorization model type.
Affects the polynomial custom kernel. It's the degree of the polynomial function. -
Fit batch size
Applies to online training extraction model types.
It's the size of the batches in which the training set gets divided. -
Inverse of regularization strength
Applies to these categorization model types:
Penalty for misclassification. It's a regularization parameter for training data. It is a number and it is used to prevent over-fitting and under-fitting. If you have a big training set and you consider it representative, the value should be small to increase the regularization and force the model to be tailored on training data. On the contrary, if you have a small dataset, which may not be representative, it is better to select large values to avoid errors.
-
L1 regularization term on weights
Applies to the XGBoost categorization model type.
Regularization alpha parameter. Lasso regularization parameter, used to reduce complexity and prevent over-fitting. When 0, no regularization is applied. The cost function is altered by adding a penalty term equal to the magnitude of the coefficients.
-
L2 regularization term on weights
Applies to the XGBoost categorization model type.
Regularization lambda parameter. Ridge regularization parameter, used to reduce complexity and prevent over-fitting. The cost function is altered by adding a penalty term equals to square magnitude of the coefficients. The penalty term lambda regularizes large coefficients by penalizing the cost function. When 0 no regularization is applied.
-
Learning rate
Applies to these categorization model types:
The rate of adaptation of the model to learning, that is how quickly the error tends to decrease.
Rising the value of this parameter shrinks the contributions of each decision tree. This means faster training but possibly less effective models. -
Left window size, CRF left window size
Applies to these extraction model types:
Number of tokens to the left of an annotation that the algorithm takes into account.
-
Max number of epochs
In online training experiments, if the maximum number of training epochs, that is the number of times the ML algorithm passes through the entire training set.
Training can stop before this number of iteration based on the value of the Patience parameter. -
N. of iterations with no changes
Applies to the GBoost categorization model type.
Parameter used as early stopping criterion. During training, if the score hasn't improved since the last iteration, the training stops. Value -1 means no improvement.
-
Normalize: penalize long documents to avoid their dominance in stats
Applies to the Complement Naive Bayes categorization model type.
When turned on, long documents are discarded to balance statistics. -
Number of trees, Number of decision trees
Apply to these categorization model types:
Number of decision trees to generate to make a decision. This value impacts on the data regularization. A high value implies a low regularization (or generalization) and a possible over-fitting. On the other hand a low value implies a high level of generalization and this involves the risk of not predicting some classes and under-fitting.
-
Optimization problem algorithm
Applies to the Logistic Regression categorization model type.
It's the algorithm to use for the optimization problem. -
Patience
Applies to online training experiments.
It's the maximum number of epochs without improvement that are tolerated before stopping iterations. -
Right window size, CRF right window size
Applies to these extraction model types:
Number of tokens to the right of an annotation that the algorithm takes into account.
-
SGD alpha regularization parameter
Applies to the SGD categorization model type.
Regularization parameter for training data. It's a number and it is used to prevent over-fitting and under-fitting. Larger values set a stronger regularization. -
Split criterion on tree nodes
Applies to the Random Forest categorization model type.
The split criterion to be applied on each node of the tree, that is the criterion to choose the branch to follow in the decision tree.
-
Stop condition tolerance, Tolerance for early stopping
Apply to these categorization model types:
It's a number indicating how much error is tolerated before early stopping. Larger values mean less iterations.
Generic parameters
Generic parameters apply to explainable categorization experiments in the Generic parameters tab.
-
Enable "onCategorizer" optimization
When enabled, categorization fine tuning is performed.
-
Enable "strict" hierarchical mode
When enabled, all ascending categories in the hierarchy are returned together with the aforementioned category.
For example, if the taxonomy models animals and the predicted category is cat then the entire hierarchical path cat > feline > mammals > vertebrates > animals is returned. -
Enable "single label" mode
If enabled, the model predicts at most one category.
Rules Generation
Rules generation parameters are described in the Rules Generation tab and they apply to these types of experiment:
- Explainable categorization
- Bootstrapped Studio project (categorization)
- Explainable extraction
- Thesaurus generation
Categorization experiments
-
Enable generation of syncon based rules
When enabled, generated rules can use the
SYNCONattribute. If disabled, also the Enable generation of ancestor based rules parameter is disabled. -
Enable generation of ancestor based rules
When enabled, generated rules can use the
ANCESTORattribute. This parameter is disabled if the Enable generation of syncon based rules parameter is disabled. -
Max number of items in each rule
Maximum number of operands in rules' conditions.
-
Max number of rules for each taxonomy category
Maximum number of rules that can be generated for each category.
-
Min number of annotated documents for a category, to enable rules generation
Minimum number of documents in which a category has been annotated that is required to generate rules for that category.
-
Max number of rules in which any single item can participate
Maximum number of rules in which a text feature (e.g. a concept, a lemma, an exact word) can be used. it's used to control the excessive generation or rules.
-
Max number of elements in a single item of a rule
Maximum number of attributes that can be used in an operand of a rule condition.
Extraction experiments
-
Maximum number of conditions for any given rule
Maximum number of conditions to use in a rule.
-
Enable automatic minimum support setup
When turned on, Platform will automatically determine the minimum support, that is the minimum number of times a rule must match inside the training set to be included in the model.
This parameter is alternative to Custom minimum support threshold (see below). -
Custom minimum support threshold
Manually entered alternative to Enable automatic minimum support setup (see above).
-
Enable automatic minimum confidence setup
When turned on, Platform will automatically determine the minimum confidence, that is the number of times a rule must match in the class target context to be included in the model.
This parameter is alternative to Custom minimum confidence to explore a rule (see below). -
Custom minimum confidence to explore a rule
Manually entered alternative to Enable automatic minimum confidence setup (see above).
-
Minimum acceptance confidence threshold
Minimum threshold to determine that a rule is acceptable. Smaller values mean greater acceptance and imply a greater final project recall.
-
Minimum confidence improvement for adding a new condition to a rule
Minimum improvement of rule's confidence that an additional condition must bring in order to be included in the rule.
-
Enable concatenation of contiguous extractions
When turned on, contiguous extractions—composed of multiple adjacent tokens—are concatenated.
Thesaurus experiments
-
Template name
Template name for output records.
-
Field name
Name of the field where the concepts are extracted.
-
File/batch granularity
Maximum number of concepts whose extraction rules are placed in a single rule file.
-
Keep longest match
When enabled, if different concepts are extracted from partially overlapping portions of text, only the concept corresponding to the longest portion is extracted.
-
Longest match type
This parameter is available if Keep longest match is selected. These options are available:
- Standard longest match strategy (default): its behavior is the same as described in Keep longest match.
- Keep results if the matched labels have the same length: other than the text portion length, this parameter considers the length of the resulting extractions in terms of number of words. If the resulting extractions have the same number of words (without considering stop words), both are kept.
-
Keep longest item
If more extractions due to rule concept entities are overlapping, the longest in terms of number of words is kept. This means that if the extractions deal with more concepts, some of them may not be extracted from the implied portion of text.
-
Forbidden forms match strategy
This parameter changes the effect of forbidden forms.
- Exact match indicates that the extraction will not occur if the concept's form exactly matches a forbidden form.
- Label window indicates that the candidate extraction will be canceled if it comes from a forbidden form found in the text.
For example, if the candidate extraction is card, found in text ... activate my credit card ..., if the forbidden form is credit card the extraction is discarded because found inside the occurrence of the forbidden form.
Note
These parameters:
- Keep longest match
- Longest match type
- Keep longest item
- Forbidden forms match strategy
are also applied to dynamic model generation experiments:
Feature options
Feature options apply to explainable extraction experiments and are described in the Feature options tab.
-
Window size (in tokens) to the left of the token being predicted
Window is a segment (set of tokens) used to find regularity in the text in order to generate rules. This parameter specifies the number of tokens to consider to the left (the precedent) of the predicted token.
-
Window size (in tokens) to the right of the token being predicted
This parameter specifies the number of tokens to consider to the right (the subsequent) of the predicted token.
-
Minimum document frequency
Minimum number of documents in which a feature (e.g. a concept, a lemma, an exact word) must be present in order to include it in a rule.
-
Raw word form
When enabled, exact words can be used in rules to match text words.
-
Word base form (Lemma)
When enabled, base forms (lemmas) can be used in rules to match the corresponding attribute of text words.
-
Word Part-of-Speech
When enabled, part-of-speech (for example noun, verb, etc.) can be used in rules to match the corresponding attribute of text words.
-
Syncons
When enabled, knowledge graph concepts (syncons) can be used in rules to match the concept expressed by text words.
-
Ancestors
When enabled, knowledge graph concepts (syncons) that, in an ISA hierarchy, are the ascendant of a given concept can be used in rules to match concepts expressed by text words.
-
Numeric words
When enabled, numeric words (like 500) can be used in rules to match text words.
-
Use suffix of a word
When enabled, word suffixes can be used in rules to match text words suffixes.
-
Use prefix of a word
When enabled, word prefixes—also called stems or roots—can be used in rules to match text words prefixes.
Fine tuning
Explainable categorization and bootstrapped Studio project experiments create models that can use JavaScript to extend and control the document analysis pipeline.
Fine tuning is performed in the Fine tuning tab with the onCategorizer event handling function, which is automatically invoked after categorization rules have been evaluated.
The Fine tuning tab is available in both explainable categorization and bootstrapped Studio project experiments. In the first case, fine tuning can be configured only if the Enable "onCategorizer" optimization parameter in the Generic parameters step of the experiment wizard is turned on.
-
Desired Clean level
Categorization results clean-up is performed with the
CLEANfunction.
The value of this parameter affects thevalueargument of that function: if set to auto in explainable categorization experiments, the fine tuning algorithm iteratively guesses the best value to use starting from the value of the Default clean level parameter (see below). This parameter is also available in bootstrapped Studio projects. -
Default clean level
Doesn't apply to bootstrapped Studio project experiments.
Initial value for thevalueargument of theCLEANfunction when Desired clean level (see above) is set to auto.Note
When the Enable "single label" mode parameter in the Generic parameters step of the experiment wizard is turned on, this parameter is ignored.
Also, if Enable conservative clean (see below) is enabled, cleanup is skipped. -
Desired filter sequence
The value to use for the
filtersargument of theFILTERfunction. It can be set to auto in explainable categorization experiments which means that the fine tuning algorithm iteratively guesses the best value starting from the value of the Default filter sequence parameter (see below). This parameter is also available in bootstrapped Studio projects. -
Default filter sequence
Doesn't apply to bootstrapped Studio project experiments.
Initial value for thefiltersargument of theFILTERfunction when Desired filter sequence (see above) is set to auto.Note
When the Enable "single label" mode parameter in the Generic parameters step of the experiment wizard is turned on, this parameter is ignored and value 100 is used to keep only the category with the highest score.
-
Enable conservative clean
Doesn't apply to bootstrapped Studio project experiments.
If no category exceeds the clean level (see above), cleanup is not performed. -
Max number of documents to be considered by the optimization algorithm
Doesn't apply to bootstrapped Studio project experiments.
Maximum number of documents used in the fine tuning process. Value -1 means no limit.
Rules selection
Rules selection parameters apply to explainable extraction experiments and they are described in the Rules selection tab. They affect the fine tuning of generated rules.
Rules are fine tuned by validating them against a subset of the training set, ranking them and selecting those with the highest scores.
-
Fine-tuning rules selecting only the most significant ones
When turned on, the rule validation and selection step is performed and all the other fine tuning parameters (see below) can be set.
-
Number of rules selection steps
Number of iterations in the rules validation and selection step.
-
Fraction of validation split
Percentage of the training set that is used by the validation and selection step.
-
Activate rules pruning
When enabled, the number of selected rules to keep and include in the model can be set with the Max number of rules to select parameter (see below).
-
Max number of rules to select
Maximum number of rules to keep after validation and selection. Rules are counted by scrolling through the list of selected rules in descending score order. This parameter can be set only if Activate rules pruning is enabled (see above).
F-Beta
F-Beta parameters apply to all experiments except:
- Explainable extraction
- Bootstrapped Studio project
- Thesaurus generation
They are described in the F-Beta tab.
F-Beta is more general way of computing the F-score. F-beta parameters affect the balance between precision and recall when computing F-Measure at the end of the test phase of the experiment.
F-Beta parameters are:
- Enable F-Beta optimization (tuning balance between precision and recall): when turned on, it is possible to set the Target F-Beta parameter.
- Target F-Beta: value 1 gives the same weight to precision and recall, values lower than 1 give more weight to precision while values greater than 1 give more weight to recall.
Auto ML parameters
These parameters apply to Auto-ML experiments when you turn on Automatic features selection in the Feature space tab or Activate Auto-ML on every parameter in the Hyperparameters tab. Such parameters are described in the Auto ML parameters tab.
In that case, Platforms trains a ML model that then uses to predict the best features and best hyperparameters' values to use when actually training the experiment model.
This assistant model is trained iteratively by passing through its training data multiple times. Its parameters are:
- Number of training iterations for the AutoML algorithm: maximum number of self-tuning iterations.
- Number of data splits for cross-validation of AutoML algorithm: number of subdivisions of training data.
- Call back function for stopping the AutoML self-tuning process: early iteration termination policy. The stop can occur when a high score is reached, when a time limit is exceeded or when a combination of a good score and elapsed time occurs.
- Target time deadline for the AutoML call back stop function (minutes): time limit beyond which the self-tuning algorithm stops iterating if a time-based early termination policy has been chosen (see the parameter above).
Structure
The Structure tab is available for Studio experiments. It has these parameters:
-
Analysis strategy for documents with layout information:
It determines how to manage graphical layout information than can be present in test documents. Test documents can have layout information if they originate form PDF files that were imported with the PDF document view option enabled.
Possible values are:
- Require layout information: only documents with layout information are analyzed.
- Use layout when available: all documents are analyzed. The model will leverage layout information—when present—if it has been programmed to do so.
- Plain text: all documents are analyzed and layout information is ignored, only the plain text is fed to the model.
-
Management of sections not compatible with the CPK:
It determines how to manage documents with incompatible sections with the model in focus. Possible values are:
- Discard document: if there are documents with sections that are not compatible with the model in focus, the document will be discarded.
- Use default section: if there are documents with sections that are not compatible with the model in focus, such sections will not be considered in the experiment.
Matching strategy
The Matching strategy tab is available for Studio extraction experiments. Use this tab to set your matching strategy.
Summary
The Summary tab is common to all experiment types. Use it to:
- Review the experiment libraries (or library in case of thesaurus experiments).
- Review all the previous parameters.
- Start the experiment.
- Set the matching strategy (for extraction and thesaurus projects).
- Review the experiment model and remapping in case of Studio CPKs.
Note
For Studio extraction experiments, the Matching strategy tab is available to set the matching strategy.
The value of the parameter (Strict, Ignore value or Ignore position) determines the strategy used to compute experiment metrics.
General
These parameters apply to thesaurus generation and dynamic model generation experiments and are described in the General tab.
-
Generate labels rules
When turned on, labels and context terms are considered when generating concept extraction rules.
-
Generate knowledge sources rules
When turned on, labels deriving from linked knowledge sources are considered when generating concept extraction rules.
-
Generate linked projects rules
When turned on, labels deriving from other projects—of which you have visibility—are considered when generating concept extraction rules.
-
Generate advanced rules
When turned on, advanced rules are considered when generating concept extraction rules.
-
Generate kill lists rules
When turned on, prevent concept extractions based on the project kill lists.
Scoring
These parameters apply to thesaurus generation and dynamic model generation experiments and are described in the Scoring tab.
Thesaurus projects based on NL Core version 4.9 or later generate explainable models with extraction rules that attribute a confidence score to extracted concepts. Rules' score can be overridden by a JavaScript scoring algorithm, embedded in the model, which behaves according to the parameters listed below.
Note
In an NL Flow workflow, the values of the parameters can be changed by setting specific options in the input JSON.
Below Scoring type, the following options are available:
- No scoring: when turned on, the score is not calculated, no tab parameters are available and the Post-processing tab is grayed out.
- Thesaurus based (labels and relations): when turned on, the generated model executes the JavaScript algorithm that overrides the confidence scores attributed by extraction rules.
- Document based (positions and frequencies): when turned on, the score is based on the frequency and the position of the mentions of the concepts in the text (see formula below before its parameters).
- Documents, thesaurus and matches based: when turned on, the score is calculated with the TF-IDF algorithm. If selected, the inverse document frequencies for terms need to be provided in IDF values in the form of an object. For example:
{"investment":5.2,"interest":8.7,"stock":3.4,"dividend":6.1,"portfolio":9.3,"asset allocation":2.9,"equity":7.5,"capital gains":4.6,"bond":8.2,"liquidity":2.3,"mutual fund":6.7,"market value":5.8,"fixed income":3.1,"risk management":9.6,"hedge fund":7.3,"credit rating":4.9,"financial planner":6.5,"pension":3.8,"retirement account":8.9,"401(k)":5.6,"debt":2.7,"budget":9.2,"savings account":4.3,"tax deduction":7.9,"inflation":3.6,"insurance":9.1,"credit score":2.4,"real estate":8.4,"net worth":6.3,"cash flow":5.5,"economic indicators":4.7,"asset management":7.7,"leverage":3.9,"dollar cost averaging":8.6,"compound interest":6.9,"credit card":2.8,"recession":9.7,"solvency":5.9,"taxable income":4.2,"bankruptcy":7.2 ...}
If Thesaurus based (labels and relations) is selected, the following parameters are available:
-
Frequency boosting: enable
When turned on, the base score for all extractions is the concept frequency in the text. This setting is alternative to Default score value.
-
Default score value
default base score for all extractions. Ignored if Frequency boosting: enable is turned on. Value 0 means no confidence score is attributed to extracted concepts.
-
Normalization Value
the final score is normalized to a value in the range between 0 and the value of this parameter. Use value 0 to disable normalization.
-
Hierarchy boosting: by parent
Multiplication factor applied to the base score based on the relationship between the extracted concept and other extracted concepts. This factor is applied for every broader concept that is also extracted from the text. Value 0 is interpreted as no multiplication.
-
Hierarchy boosting: by children
Multiplication factor applied to the base score based on the relationship between the extracted concept and other extracted concepts. This factor is applied for every narrower concept that is also extracted from the text. Value 0 is interpreted as no multiplication.
-
Hierarchy boosting: by related
Multiplication factor applied to the base score based on the relationship between the extracted concept and other extracted concepts. This factor is applied for every non-hierarchically related concept that is also extracted from the text. Value 0 is interpreted as no multiplication.
-
Label boosting: preferred label matched
Multiplication factor applied to the base score if the matching text is the preferred label. Affected by Label boosting: ignore case.
-
Label boosting: alternative label matched
Multiplication factor applied to the base score if the matching text is one of alternative labels. Affected by Label boosting: ignore case.
-
Label boosting: length measure
Multiplication factor applied to the base score corresponding to the number of tokens—separated by space—of the match. Affected by Label boosting: ignore case.
-
Label boosting: ignore case
When turned on, the case is ignored when matching the text and the labels of the concept. This settings affects:
- Label boosting: preferred label matched
- Label boosting: alternative label matched
- Label boosting: length measure
If Document based (positions and frequencies) is selected, the formula to calculate the score is:
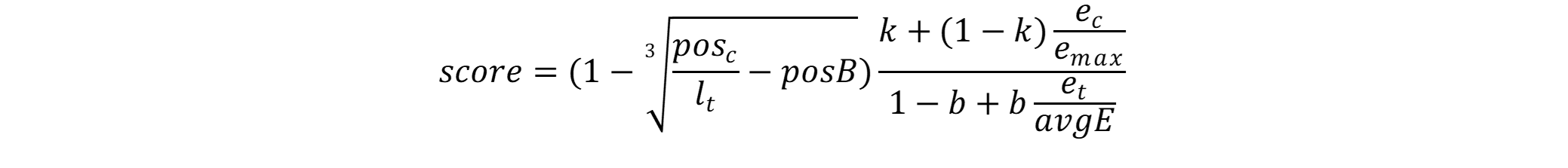
where:
poscis the zero-based start position in the text of the extraction.ltis the length of the text in characters.posBis a parameter (see below).kis a parameter (see below).ecis the number of extraction for the concept.emaxis the number of mentions of the concept that has more extractions.bis a parameter (see below).etis the total number of extractions.
If this parameter is selected, the following parameters are available:
-
K
Positive tuning parameter to normalize the document term frequency. Value between 0 and 1—0.5 by default—where 0 means pure relative frequency.
-
B
Positive tuning parameter that determines the scaling by document length. Value between 0 and 1—0.5 by default—where 1 corresponds to fully scaling the term weight by the document length, and 0 corresponds to no length normalization.
-
avgE
Average number of extractions per document in the document set. Number greater than 0, 1 by default.
-
posB
Position bias. It boosts the score if the extraction appears in a specific part of the document. Number between 0 and 1, 0.25 by default.
If Documents, thesaurus and matches based is selected, select an IDF value set—generated in the Documents tab—in the Select IDF dropdown menu below IDF values or upload it by selecting Upload file. The Concepts and JSON tabs—already described in the dedicated page— will appear.
Post-processing
These parameters apply to thesaurus generation and dynamic model generation experiments and are available in the Post-processing tab. If No scoring is selected below Scoring type in the Scoring tab, the panel in focus is grayed out.
The parameters of this family relate to the score of the extracted concepts.
-
Score threshold
Extracted concepts with a score below this threshold get discarded. Value 0 means infinite threshold, no concept gets discarded.
-
Narrower score thresholds
If the score of an extracted concept is greater of equal to this threshold, any broader concept discarded; in other words, narrower concept "win" over their broader concepts if they score enough. Value 0 means infinite threshold, so the score of the narrower concept can never be high enough to cause its broader concepts to be discarded, so no concept gets discarded.
-
Boost results in specific sections
This parameter determines a boost of the score of concepts extracted from given sections. The value has this syntax:
sectionName1=scoreMultiplier1[, sectionName2=scoreMultiplier2, sectionName#=scoreMultiplier#]where:
sectionName#is the section name.scoreMultiplier#is the a score multiplier and determines the boost: the score of the concept is multiplied by this value.
The project must have defined sections for the score boost to take effect.
-
Max results
Maximum number of concepts extracted from a document. The concepts extracted from a document are sorted by score, in descending order, and only the first n are kept. Value 0 means theoretically infinite results, no cut is performed.
Languages
The Languages tab is the first step of the dynamic models generation wizard in a thesaurus project.
It shows all the project's languages and allows choosing the language for which dynamic models will be generated.
In case of multiple languages, the favorite one is marked with a star.