Interpret segmentation outcome
The segmentation results, that is the segments detected by rules during a text analysis, are displayed in the Segments tool window.
Note
It is necessary re-analyze a test file—or all test files—included in the module if rules or test files have changed.
This operation is performed on the current test file. It is possible to check the filename in the tool window title bar.

The Segment/Rules panel
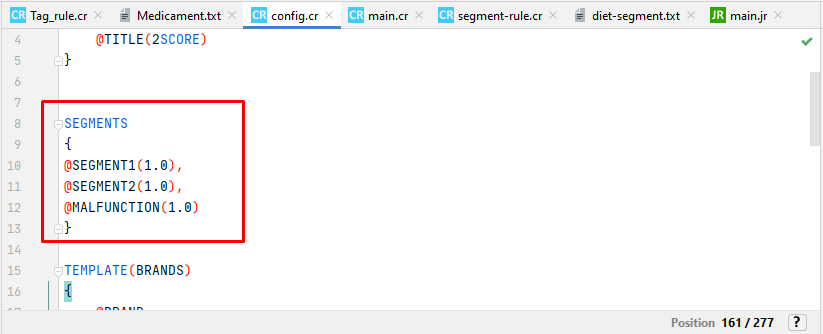
The Segment/Rules panel shows a list of segments. This means that one or more triggered rules detected one or more segments that were declared with SEGMENTS in the config.cr file and specified with SEGMENT in the rule.
It is possible to expand/collapse each row by selecting the toggle switch in the row left side or expand/collapse all the rows by selecting Expand All/Collapse All  on the tool window toolbar.
on the tool window toolbar.
The expand/collapse toggle switch on the left also displays or hides the segment instances. There are one or more rows for each instance. The expand/collapse toggle switch on the left also displays or hides the rule code.
Example
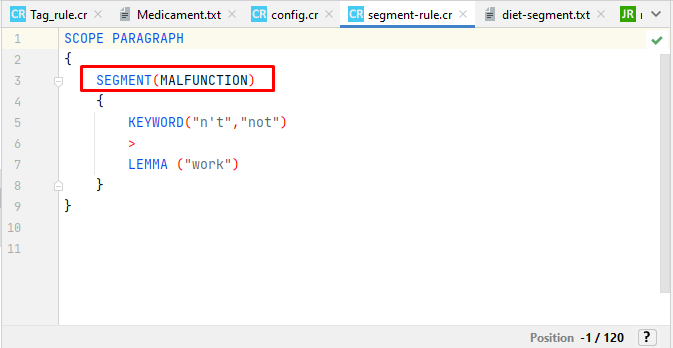
Considering the rule:
SCOPE PARAGRAPH
{
SEGMENT(MALFUNCTION)
{
KEYWORD("n't","not")
>
LEMMA ("work")
}
}
and the text:
About a month ago I was diagnosed with "pre-diabetes" after a blood test.
I had complained to my doctor of constant tiredness and lack of energy throughout the day.
I will be the first to admit my diet is lousy - pizzas, burgers, chocolate, takeaways, fizzy drinks are all vices of mine.
I only buy ready-made foods, because my oven doesn't working properly.
To help me monitor this I purchased this accu-check gadget and although the concept of taking my own blood samples was a bit daunting, it really is very easy indeed.
Unfortunately, in the last days my blood glucose monitor seems to give incorrect readings.
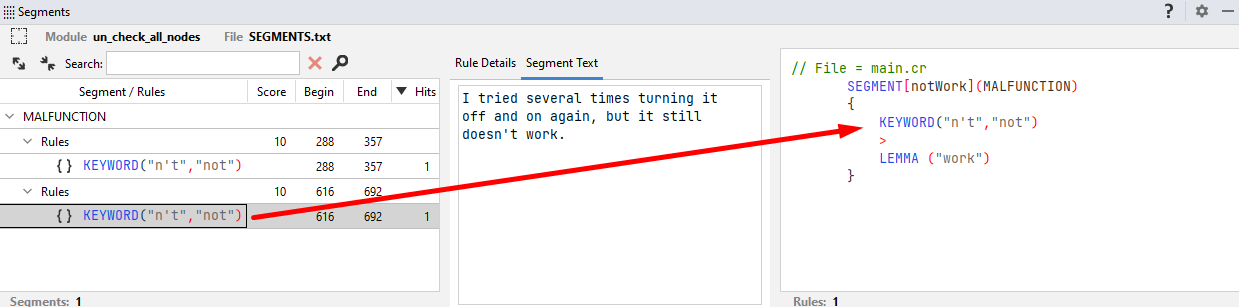
I tried several times turning it off and on again, but it still doesn't work.
the rule detects MALFUNCTION two times. These instances are called Hits.
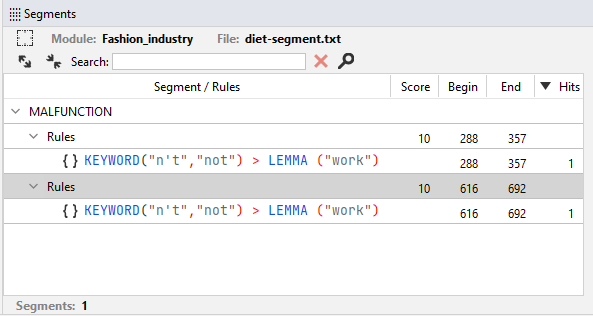
Considering the segment, if the score option is omitted or set to NORMAL (NORMAL = 10) the result score, shown under Score in the panel, counts 10 for each hit, that is 20 in total.
The panel also displays the starting and ending positions of the sentence in the text where the segment was found.
Clicking on the segment name shows the two sentences (in light orange) where the rule hits (in blue) are found.
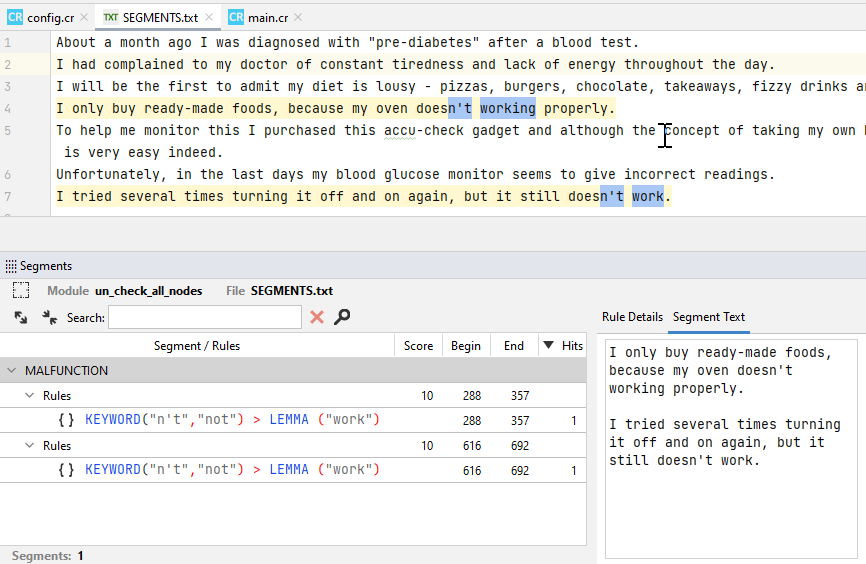
Clicking on a single rule instance shows:
- The sentence (in light orange) where the rule hit is found (in blue).
- The Rule Details/Segment Text panel.
- The Rule preview panel on the right.
It is possible to change the order of each panel column by clicking its header.
The Rule Details/Segment Text panel
This panel is composed of two tabs:
- The Rule Details tab shows the hit rule and its label (if specified).
Note
Rule labels are optional. See the language reference documentation to learn how to insert rule labels in a rule.
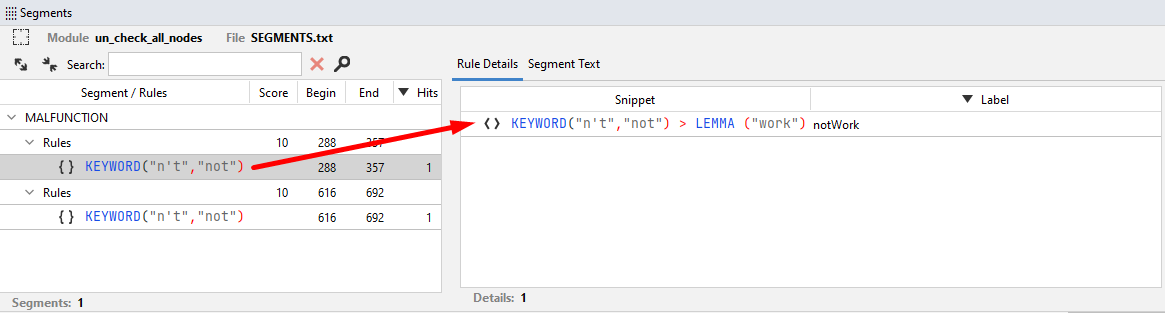
-
The Segment text tab shows the sentence where the hit is found.
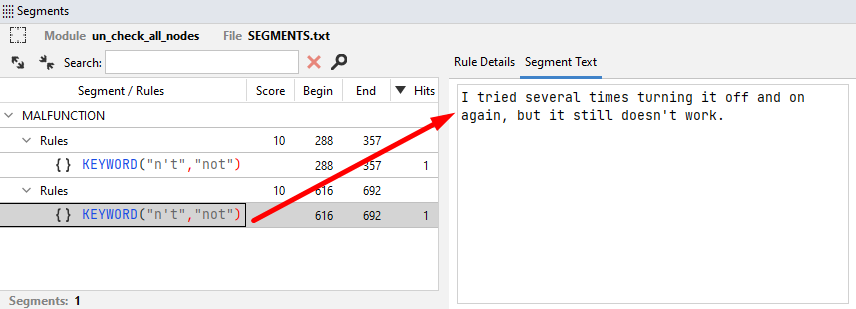
The Rules text panel
This panel displays the rule code.