Make experiments
Overview
Once the resources and the concepts have been set up and the documents have been annotated, you can start experiments that consist of creating a model and applying it to a library.
An experiment process is based on:
- A library.
- An engine.
The library, or data set, consists of an annotated document set that helps the engine to learn.
The engine parses the test library in order to give the analysis results.
Platform provides one type of engine for thesaurus projects, namely Thesaurus generation.
To start an experiment:
- In the upper bar, select Start an experiment
 .
. -
In the Start an experiment window:
- Enter the experiment name in Name or leave the bar empty for an automatic one.
- Select the Test library, then select Next.
-
Check the summary, then select Start.
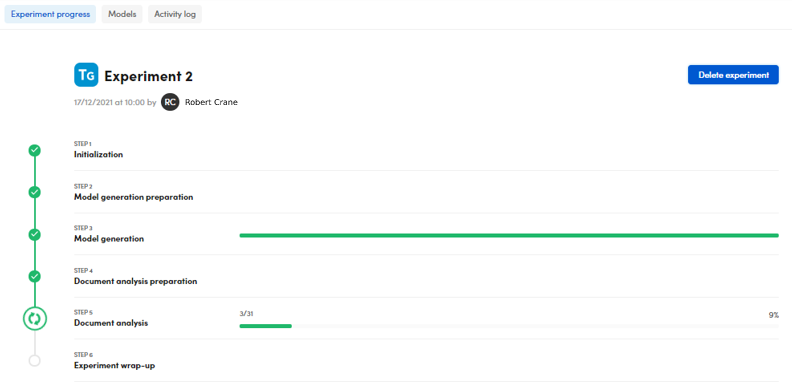
The run progress window is displayed during the engine process.
Note
To terminate the process before its end, select Delete experiment.
The process consists of six sequential stages:
- Initialization
- Model generation preparation
- Model generation
- Document analysis preparation
- Document analysis
- Experiment wrap-up
Once the process is completed, the analytics are displayed in the Statistics sub-tab and you can start to interpret the results.
Note
If the experiment fails, the tab Info appears displaying information and the type of errors. You can check also the Activity log tab for further information.
Experiments without annotations
If you run an experiment on libraries without annotations there are no quality indicators and the tab is displayed in the following form:
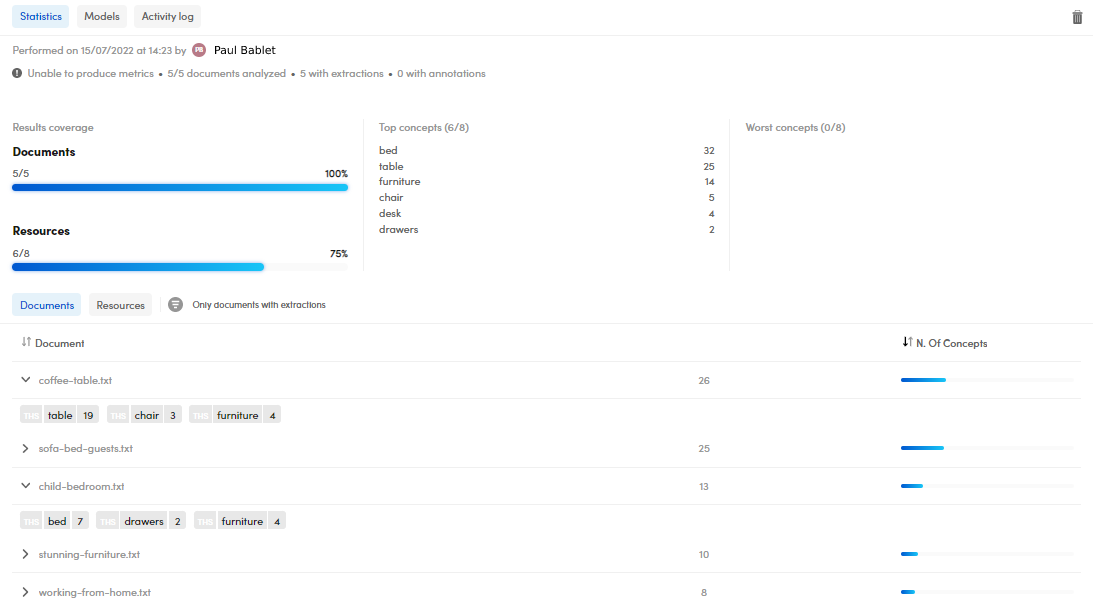
Information displayed:
- Experiment name.
- Performance date and time.
- Author of the experiment.
- Number of analyzed documents.
- Number of documents with extractions and with annotations.
The Results coverage panel lists the number and percentages of Documents in which some of the Resources have been automatically spotted.
The Top concepts panel lists the the most automatically recognized concepts in your documents, vice versa for the Worst concepts panel.
The Statistics panel is composed of the following sub-panels:
- Documents, listing the analyzed documents.
- Resources, listing the automatically recognized resources.
Documents
- Select the expanding
 or the collapsing arrow
or the collapsing arrow  to expand or collapse the documents and see the extractions.
to expand or collapse the documents and see the extractions. - Hover over a document and select Annotate document
 to open it in the Documents tab, detail view and start annotating it.
to open it in the Documents tab, detail view and start annotating it. - Hover over a document and select Open document
 to open it in the Experiments tab, Documents statistics sub-tab.
to open it in the Experiments tab, Documents statistics sub-tab. - To sort your documents according to the number of recognized concepts, select the arrow beside the column header on the right.
Filter documents with extractions
Click the icon beside Only documents with extractions till turns in one of the following forms:
 to select the positive filter, that means only documents with extractions.
to select the positive filter, that means only documents with extractions. to select the negative filter, that means only documents without extractions.
to select the negative filter, that means only documents without extractions. means no filter.
means no filter.
Resources
- Hover over a concept and select Search
 to perform a search according to the concept in focus.
to perform a search according to the concept in focus. - Hover over a concept and select Show in resources
 to show the concept in the Resources panel.
to show the concept in the Resources panel. - Hover over a concept and select the information icon
 to show, in case of no annotations, the preferred label only.
to show, in case of no annotations, the preferred label only. - Select the arrow beside the column header to sort the concepts according to their hits.
- Select a concept to view its labels and relations under Resource details.
- Under Resource details, RELATED CONCEPTS, select the resources icon
 to view the concept in the Resources tab.
to view the concept in the Resources tab.