Edit project settings
Overview
See the dedicated article to know how to access project settings and manage settings that are common to several project types. Settings that are specific of thesaurus projects are grouped in the tabs described below.
Languages
The Languages tab allows you to set the project languages and choose the favorite language between them.
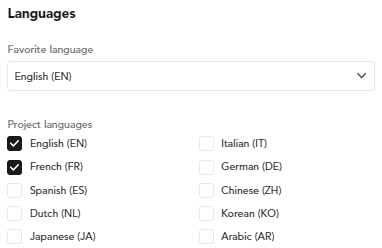
If you check only one language, it will be automatically set as the favorite.
Thesaurus URI
The Thesaurus URI tab allows you to define the prefixes for the URIs of the thesaurus's concepts and the other parts that compose the URIs.

- To add a new URI prefix, select Add new URI prefix and enter the new prefix.
- To change an existing prefix, just select and edit it.
- To delete an existing prefix, hover over it and select the trash bin icon
 .
. -
If you have to use characters that are not allowed in an URI, like white spaces, hover over the prefix and select Encode uri
 to create an URL-encoded version of it.
to create an URL-encoded version of it.Note
You can delete an existing prefix only if there is at least another prefix defined.
-
To determine the parts that constitute the full URL for a given prefix, select the prefix and then select the parts that can be:
- Project name
- Concept label plus optional concept ID
-
When done, select Save.
DataTypes
In this tab you can manage the data types that you can attribute to the individual values of the custom properties of a concept with a form type set to Text.
- Under Basic DataTypes are listed the data types taken from http://www.w3.org/2001/XMLSchema. The default data type selected is #string. This means that each time you create a custom property with a form type set to Text the data type will be set to http://www.w3.org/2001/XMLSchema#string.
- Under Custom DataTypes are listed the data types automatically taken from imported taxonomies or subtrees and any other user-defined data types.
To add a custom data type:
- Select Add new DataType. A new text box appears.
- Type the data type URL in the new text box. If you have to use characters that are not allowed in an URI, like white spaces, hover over the prefix and select Encode URI to create an URL-encoded version of it.
- Click anywhere in the dialog outside the text box.
To delete a custom data type, select the data type and then select the trash icon .
Select Save to commit the changes.
Extraction
The models generated during experiments extract the occurrences of the thesaurus concepts from documents. In the Extraction tab you find the settings that affect extraction and validation. These settings are used as default values for new concepts and can be overridden at the concept level.

Extraction method
Extraction method is the way generated models will use concepts' labels to determine the portions of text to extract.
Possible methods are:
- Semantic: all the portions of text expressing the same meaning of the concept labels, in any inflected form. For example, if the label is sandglass, the model will extract sandglass, hourglass, sandglasses, hourglasses.
- Fuzzy matching: valid for collocations, the method extracts the concept even if the collocation words do not appear in the order in which they are written in the label, as long as they are within a certain maximum distance not established by the user.
- Base form: the label is considered as a lemma (the base form or dictionary entry for a term) and all the inflections of it are extracted. For example, if the label is sandglass the model will extract sandglass and sandglasses.
- Exact label: the model will extract exact matches of the labels.
- Exact label same case: the model will extract exact labels by case sensitive matches. For example, if the term contains at least one uppercase character, the match is case sensitive. For example, Triumph matches only Triumph.
-
Exact label case insensitive: the model will extract exact labels by case insensitive matches. For example, if the term is written in lowercase, like triumph it will match:
- triumph
- Triumph
- TRIUMPH
- ...
Approval status
In this panel you can set the default approval status for new concepts. See the article dedicated to the topic for further information.
Context settings
The context is the subdivision of the text or the sequence of subdivisions in which to search for the expressions of the concept to be extracted.
Warning
Not all parts of a text correspond to clauses. For example, a heading like:
Disclaimer
may not be considered a clause, so be aware that if you set Clause as context, there may be portions of the document text in which extraction will not take place.
The context also serves in combination with the specification of terms that must or must not co-occur in the vicinity of the term corresponding to the concept to be extracted. Co-occurrence constraints can be set at the concept level.
Experiments
In the Experiments tab, other than the metrics policies and the matching strategy, set:
- The template name for output records in Template.
- The field name where the concepts are extracted in Field.
Suggestions
In the Suggestions tab you can check and set the settings that determine which suggestions are displayed when you edit a concept.

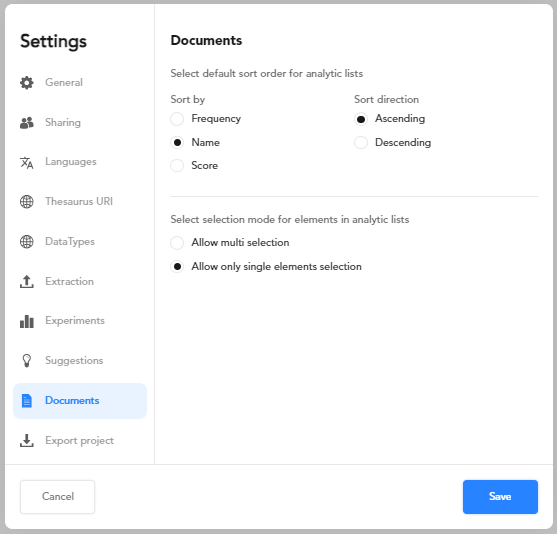
Documents
Use the Documents tab to manage sorting and selection of your facets and annotations and extractions of the Thesaurus tab when in detail view.
-
Select the sort option and the sort direction. You can sort in ascending or descending order by:
- Frequency
- Name
- Score
Note
More details in the dedicated paragraph.
-
Select:
- Allow multi selection to allow multiple selection of your facets.
Or:
- Allow only single elements selection to allow a single element selection of your facets.
-
When done, select Save.