Test rules
The rule testbed is useful for testing rules in a specific context, especially if the project is complex and huge and therefore requires a lot of time and resources to be fully built.
It is also suggested when you want to identify which sentences and text fragments trigger the rules and this helps to evaluate their impact in the project.
Essentially the rule testbed starts a new analysis context that does not consider the current project rules; it has visibility only on the taxonomy and on the definition of the templates and not on scripts and other advanced language elements.
This feature is available for the Enterprise Edition.
Start the rule testbed
- Select a file or a set of file (multiple documents selection with
CTRL-clickor folder selection are allowed) in the Project tool window. - Right-click the selected files or folders, then select Rule Testbed.
-
Write the rule (or the rules) to test in the Rule Testbed window, in the upper left panel.
Note
Writing one or more rule in this panel text area means write rules with no dependency from external elements like tags, lists, and so on.
In this area a user can also write a rule fragment, for example only the constraint part of a rule, that means with no
SCOPE, noIDENTIFY, noDOMAIN.Example
LEMMA("cat") >> TYPE(NPR)This rule works as a query against the documents to select those fragments where cat is strictly followed by a proper noun.
-
Select Rule Testbed
 to check the rule against the documents.
to check the rule against the documents.
Note
After this procedure, you can also open the Rule Testbed window by selecting Rule Testbed  in the lower right corner of an opened rule file in the editor.
in the lower right corner of an opened rule file in the editor.
The Rule Testbed window
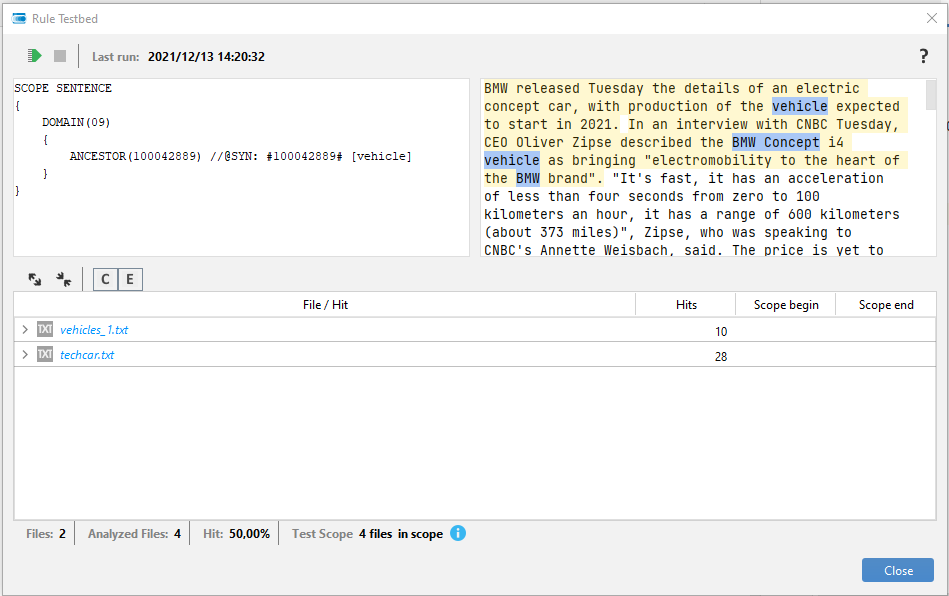
The Rule Testbed windows is composed of the following panels and a status bar info:
- The upper left panel is used to write the rule.
-
The upper right panel displays the possible test document selected in the lower panel.
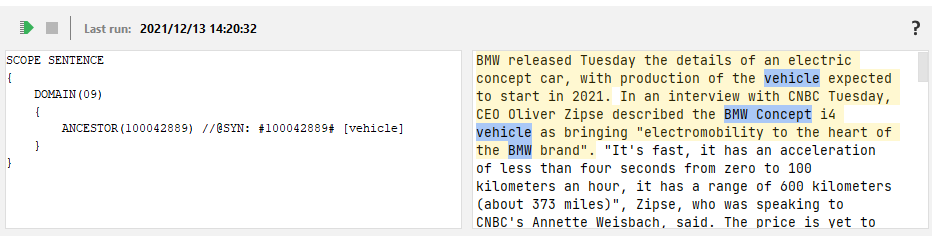
The upper toolbar contains:
Icon Name Description **Rule Testbed ** Test a rule against the document. 
Stop Abort current analysis. Last Run Last Rule Testbed date and time. -
The lower panel displays the list of the documents in which the text fragments triggered the rule.
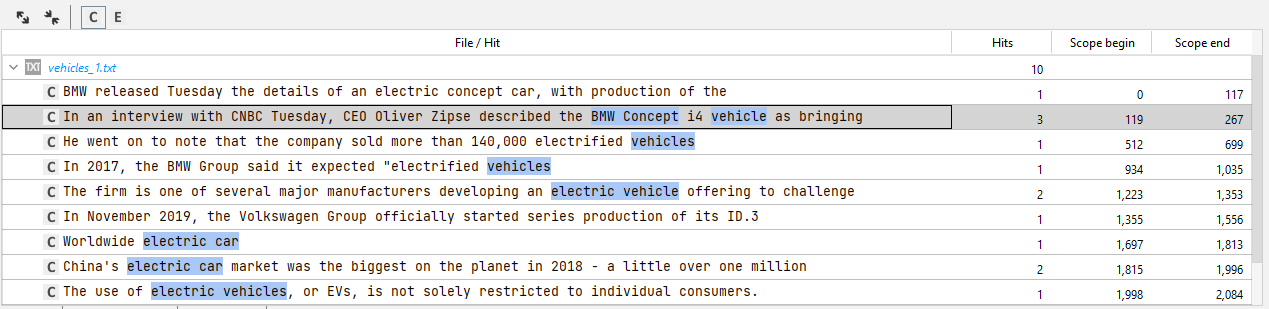
The columns are:
Name Description File/Hit The document that triggered the rule and the hits in the sentences. Hits Document hits number. Scope begin Starting position of the hit in the sentence. Scope end Ending position of the hit in the sentence. The lower toolbar contains:
Icon Name Description 
Expand All Expand all the nodes of the tree for a more detailed view. 
Collapse All Collapse all the nodes of the tree for a more compact view. 
Categorization Data Toggle categorization data visibility. 
Extraction Data Toggle extraction data visibility. Note
Rule Testbed works only on Categorization and Extraction rules.
-
The status bar info displays:
Name Description Files Number of documents that triggered the rules. Analyzed Files Number of analyzed files. Hit Percentage of files that triggered the rules. Test Scope Number of selected files.
Test Scope
Select Test Scope  to open the Annotation Files window displaying all test documents in scope and their properties.
to open the Annotation Files window displaying all test documents in scope and their properties.
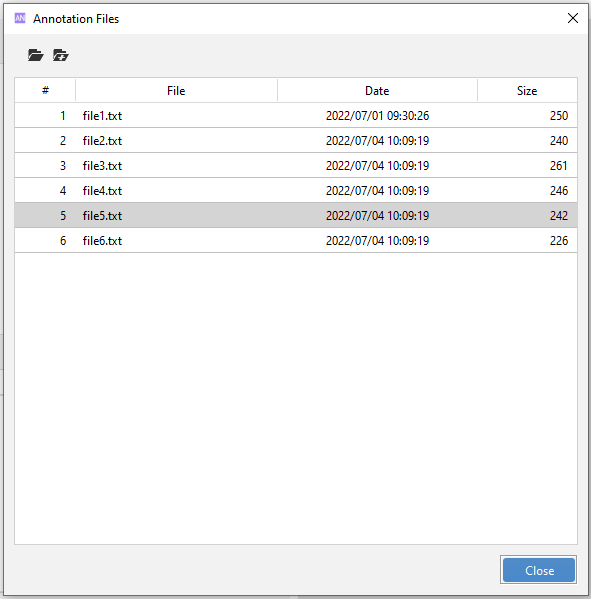
The dialog contains these columns:
| Name | Description |
|---|---|
| # | Selection order number of the file |
| File | File name |
| Date | File creation date and time |
| Size | Number of characters |
To open all test files in the editor, select Open all Test Files  .
.
To open a single file in the editor:
- Select a file, then select Open Test File
 .
.
Or:
- Double-click a file.
Testbed results
Once the rule testbed process is completed, it is possible to check in the lower panel if the selected documents triggered the rules.
- Select
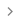 to expand the hits.
to expand the hits. -
Select a row to check the hits (highlighted in blue) within the sentence (highlighted in pale yellow) in the upper right panel.
Note
Each row is marked with an icon that specifies whether it is a categorization
or an extraction result.
Select Categorization Data
or Extraction Data in the toolbar to filter the results type.