Studio programming languages
The languages
Welcome! This is the reference guide of Studio programming languages.
Studio programming languages are used to write the source code of a unique type of software: text intelligence engines. Text intelligence engines are programmed to perform tailored document classification and information extraction.
If you are looking for information on the integrated development environment (IDE), see the Studio user manual.
There are two Studio languages:
- Rules language.
- Scripting language.
The core of text intelligence engines is written with rules language, while scripting is optional and used to control and extend the process workflow.
The rules language is a declarative language, because it doesn't implement algorithms in explicit steps. Essentially, the source code is a set of rules.
Categorization
Document classification is the activity that a human mind or a computer program performs whenever a decision needs to be taken or a task needs to be executed based on the document type or on the topics covered by the document.
For example, in order to give a proper answer to a customer's request, the type of request must be determined.
Text intelligence engines classify documents with a process called categorization, that strives to determine what a document/text1 is about. The possible categories are called domains and the entire set of domains the engine is able to recognize is called taxonomy.
The core of the categorization process is to compare categorization rules with the text. Each rule is made of a condition and a domain: if the text satisfies the rule's condition, the domain will receive a certain amount of scoring points.
At the end of the process, the domains with the received points constitute the categorization outcome.
An example of categorization by comparison is the recognition of military aircraft during the Second World War. To determine whether the planes were friends or foes, military personnel had playing cards, tables and posters showing the silhouettes of military planes. Comparing the shapes in their cards with those of the airplanes flying over them, they could "categorize" airplanes as either "good" or "bad" and, in the latter case, raise the alarm.
U.S. Air Force photo by Ken LaRock, VIRIN: 170921-F-IO108-001.JPG
Extraction
Information extraction is the activity that a human mind or a computer program performs to detect needed data in a document.
For example, to correctly associate a customer's request with the customer's record, the customer's identification data like first name, last name or customer code must be extracted from the request.
Text intelligence engines perform information extraction to retrieve useful data out of a document/text by comparing extraction rules with the text.
As for categorization rules, extraction rules contain a condition, but instead of a domain, they are associated with a data template: if the text satisfies a rule's condition, the text that matches the condition as a whole or parts of it will be transferred—verbatim or after a value normalization—in template fields that together constitute an extraction record.
At the end of the process, records constitute the extraction outcome.
Rules
As anticipated above, a rule is a combination of a condition and an action.
The action is performed whenever the condition is met: in categorization the action is: "increase the score of the associated domain by N points", while in extraction it is: "fill data template fields with the text matched by the conditions or by the sub-conditions".
A condition can be equated to a rigid or elastic shape. The disambiguator—the text analysis module at the heart of expert.ai technology—transforms the input text into a sequence of tokens, each enriched with all the attributes that the disambiguator has identified during its analyses. The text intelligence engine takes each defined rule and "superimposes" its condition (the aforementioned "shape") to the token stream. Whenever the "shape" fits perfectly a portion of the stream or, less commonly, the entire stream, the condition is satisfied and the rule's action is performed. It can be said that the input tokens trigger or activate the rule.
A text intelligence engine's source code can thus be considered as a collection of possibly overlapping shapes which capture topics clues or interesting data.
Like the World War II "spotter cards" mentioned above, or swatches used to match paint colors, the larger the assortment of rules, the greater the ability to recognize interesting cases. At the same time avoid creating (and then having to maintain over time) rules that are not necessary for the purposes of the project.
The condition of a rule can also be seen as a "text template" or "text model": if the template/model matches the input text, then the rule will be activated.
In general, there is no explicit order of evaluation of the rules of the same type; it is as if all of the defined rules got evaluated simultaneously. The only exceptions to this principle are sub-rules, which, if defined, are necessarily evaluated before rules.
Other types of rules and the analysis pipeline
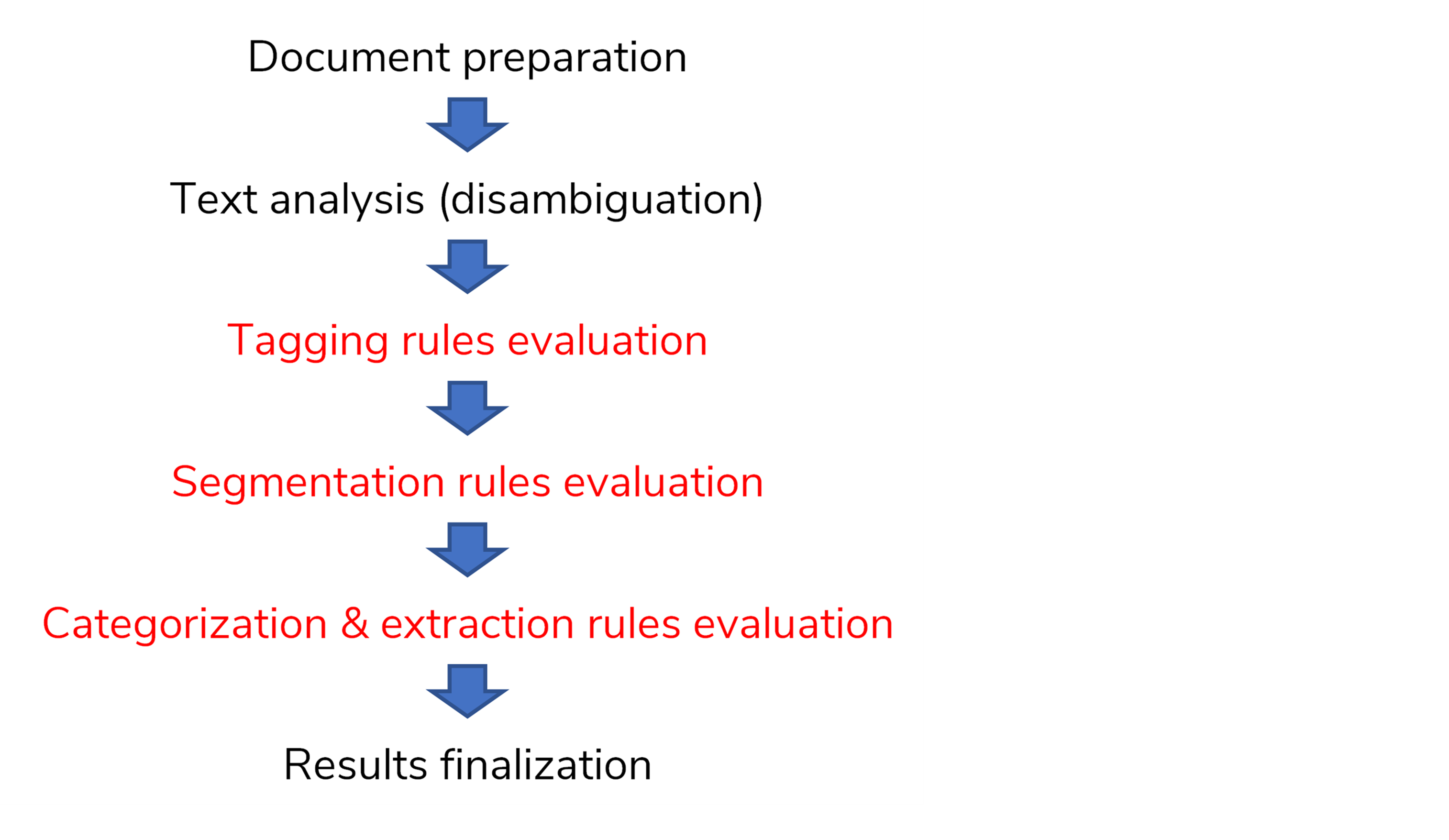
A programmer can also define tagging and segmentation rules. Rules of these types do not categorize or extract, but their results—tags and segments—can be exploited in categorization and extraction rules.
The rules evaluation order is:
- Tagging rules
- Segmentation rules
- Categorization & extraction rules
Rules evaluation is the core of the analysis pipeline (see the picture below) that the text intelligence engine executes for every input document.
Rules language features and this book
There are language constructs which are specific to the categorization activity and there are those which are specific to extraction activity. However, the rules language also has many features which are common to both activities.
This book has been divided into sections according to these commonalities and peculiarities. Segmentation rules are dealt together with the common features, while a specific section is dedicated to tagging rules.
Scripting language
Text intelligence engines allow you to use scripting at key points in the document analysis pipeline, from the preparation of input text to the finalization of results. This allows you to extend and control the pipeline in a very powerful way.
Studio scripting language is "JavaScript like", so that everyone knowing JavaScript can easily use it.
Note
Do not confuse the language with the usage. JavaScript is the primary language used in Web browsers for making pages dynamic, but text intelligence engines are not browsers, and Studio scripting serves other purposes not directly related to Web browsing.
An entire section of this book is dedicated to scripting.
-
Throughout this guide the terms "document" and "text" are used interchangeably because document is intended as "the document's text".
In light of this interpretation, a document can be:
- Any plain text file.
- The text of a "textual" PDF file.
- The text taken from an image like a scanned document or from a "visual" PDF file via OCR.
- The caption of a photograph.
- The transcript of a phone call.
- A line from a chat.
- The text of an e-mail message.
- A "tweet".
- A post in a forum or a comment to a post.
- The value of a field in a screen form. ... in summary: any string of characters from any source