SCRIPT
Overview
SCRIPT transformation option allows changing extracted values with scripting functions. Both built-in or user-defined functions can be used.
Consider this example using the toUpper built-in function:
SCOPE SENTENCE
{
IDENTIFY(TEST)
{
@FIELD1[LEMMA("twenty")|[SCRIPT("toUpper")]
}
}
If the rule is applied to this input text:
Jane and Markus married twenty years ago
you will get:

The rule extracts TWENTY, uppercase, when extracted text originally was lowercase.
SCRIPT can be combined with the other transformation options with the plus (+) sign. Such a combination allows a sequential action of the transformers (see an example for the winnerTag built-in function below).
The syntax of the SCRIPT transformation option in an extraction rule is:
SCOPE scopeOption
{
IDENTIFY(templateName)
{
@field[attribute]|[SCRIPT("function1 name[:parameter]" [, "function2 name[:parameter]" ...])]
}
}where parameter is an optional parameter of the function.
Apart from those around attribute and SCRIPT, all the other square brackets indicate optional parts.
When more functions are specified, one function acts on the outcome of the previous and the value that is actually extracted is that coming out from the last function.
User-defined functions
User-defined functions must be defined in the main.jr file.
Their definition must have this syntax:
function name(tokenID, extraction, parameter)The name of the parameters does not matter, but their position corresponds to their role and they must all be declared, even if not used in the body of the function.
In the first parameter the text intelligence engine, when it invokes the function during the extraction of the field, passes the ID of the text token it is examining. This, combined with the methods of the DIS pre-defined object, allows for sophisticated transformations based on the properties of the token.
In the second parameter the engine passes, as a string, the value extracted up to that moment.
In the third parameter, the engine passes the value of any parameter specified in the rule, after the name of the function and the colon. This allows for parametric transformations, calling the same function, but with different parameters based on the condition or rule.
The function must return a string, and the engine uses that return value as the new value of the current extraction.
Built-in functions
These are the built-in functions that can be used with the SCRIPT transformation option:
toUppertoLowerreplaceStringwinnerTag
toUpper
toUpper turns the extracted value into uppercase. Consider the example above to see how it works.
This function does not have a parameter.
toLower
toLower turns the extracted value into lowercase. Consider this example:
SCOPE SENTENCE
{
IDENTIFY(TEST)
{
@FIELD1[KEYWORD("ROSE")]|[SCRIPT("toLower")]
}
}
If this rule is applied to this text:
He bought me a ROSE.
you get:

This function does not have a parameter.
replaceString
replaceString replaces all the occurrences of a string with another in the extracted value.
For example, if this rule:
SCOPE SENTENCE
{
IDENTIFY(BUSINESS_STATS)
{
@LENGHT_OF_TIME[KEYWORD("qt")]|[SCRIPT("replaceString:qt|qtr")]
}
}
is applied to this input text:
Profit is up 12% in 3rd qt.
you get the extraction of qtr instead of qt.
The replaceString function has a parameter, the syntax is:
replaceString:stringToReplace|replacementStringwinnerTag
The winnerTag function returns the names of token's tags that match its parameter.
It is used in combination with the TAG transformation option, when the extraction corresponds to a token with multiple tags.
Consider this example where this situation occurs
TEMPLATE(INJURY)
{
@TYPE_OF_INJURY,
@LOCATION_OF_INJURY
}
TAGS
{
@INJURY_TYPE,
@INJURY_LOCATION
}
...
SCOPE SENTENCE
{
TAGGER()
{
@INJURY_TYPE[SYNCON(105781808)] // backache
}
TAGGER()
{
@INJURY_LOCATION[SYNCON(105781808)] // backache
}
IDENTIFY(INJURY)
{
@TYPE_OF_INJURY[TAG(INJURY_TYPE)]|[TAG + SCRIPT("winnerTag:INJURY_TYPE")]
}
}
If the extraction rule is applied to this text:
The patient suffers from backache.
the backache token is tagged twice since it indicates both the type of injury and its location. If the extraction rule was:
IDENTIFY(INJURY)
{
@TYPE_OF_INJURY[TAG(INJURY_TYPE)]|[TAG]
}
the extraction would be:
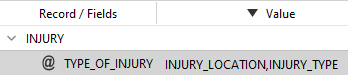
that is the concatenation of both tags.
The winnerTag functions selects only the tag specified as its parameter, so the value of the extraction becomes the name of that tag. i.e. INJURY_TYPE.
The syntax of winnerTag is:
winnerTag:tagName1[|tagName2 ... ]or:
winnerTag:tagListPath[|tagListPath2 ... ]where tagListPath refers to the path of the list file containing tag names.