mergepost
Overview
The mergepost module allows you to manipulate the extraction output.
It has the following methods:
FIELD_CLONEMERGE_BY_VALUEMERGE_BY_INSTANCEMERGE_BY_INSTANCE_BEGIN_ONLYREPLACE_FIELD_VALUERECORD_CLONEloadapplygetLastError
When in Studio you install the mergepost module in your project, Studio modifies the main.jr file to insert this statement at the beginning of the file:
var mergepost = require("modules/mergepost");
The statement above sets a variable with an instance of the module so that you can use it inside event handling functions.
FIELD_CLONE
The FIELD_CLONE method creates a new field whose value is a copy of the value of an existing field.
It must be used in the onFinalize function when extractions results are available.
Consider the following template:
TEMPLATE(PERSONAL_DATA)
{
@NAME,
@NAME_INITIALS,
@ADDRESS,
@PHONE
}
When the following rule:
SCOPE SENTENCE
{
IDENTIFY(PERSONAL_DATA)
{
@NAME[TYPE(NPH)]
}
}
is applied to this text:
Sherlock Holmes is a private investigator.
you get:
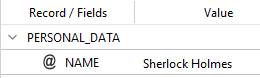
With this code:
function onFinalize(result) {
mergepost.FIELD_CLONE(result, "PERSONAL_DATA", "NAME", "NAME_INITIALS");
return result
}
the output becomes:
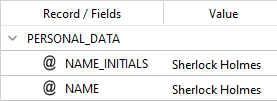
In a common use case, the value of the new field is then processed. You can see an example of this in the description of the REPLACE_FIELD_VALUE below.
The syntax of the method is:
moduleVariable.FIELD_CLONE(result, templateName, fieldName, cloneFieldName)where:
moduleVariableis the variable corresponding to the module and set withrequire().resultis the object containing the analysis results.templateNameis the template name of the records in which to create the new field. It can be an asterisk (*), which means "any template".fieldNameis the name of the field to clone.cloneFieldNameis the name of the clone field.
MERGE_BY_VALUE
The MERGE_BY_VALUE method merges all the records of a template when they have the same value for one or more given fields.
It must be used in the onFinalize function when extraction results are available.
For example, consider the following template:
TEMPLATE(PERSONAL_DATA)
{
@Name,
@Job,
@Product,
@Company,
@Role
}
If these rules:
SCOPE SENTENCE
{
IDENTIFY(PERSONAL_DATA)
{
@Name[TYPE(NPH)]
<1:5>
@Role[LEMMA("purchaser")]
<1:4>
@Product[KEYWORD("iPhone")]
}
IDENTIFY(PERSONAL_DATA)
{
@Job[LEMMA("software engineer")]
<1:5>
@Company[TYPE(COM)]
<1:4>
@Name[TYPE(NPH)]
}
}
are applied to this input text:
John Markovitch is the first purchaser of the new iPhone. The best software engineer for Samsung is John Markovitch.
you will get:
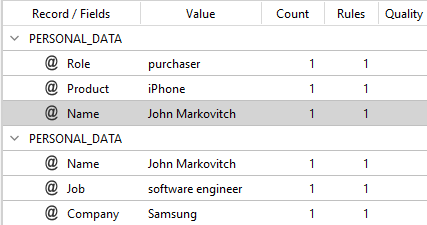
As you can see, there are two records about the same person (John) with different information.
If the rules above are applied to the same input text and you have this code:
function onFinalize(result) {
mergepost.MERGE_BY_VALUE(result, "PERSONAL_DATA", ["Name"])
return result;
}
you will get the following output:
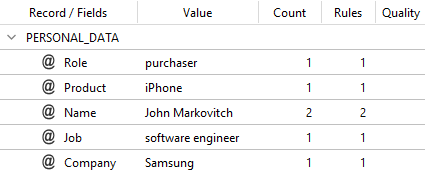
The MERGE_BY_VALUE method gathered all the information around the "attractor field" value, in this case John for field Name, creating a unique record.
The syntax of the MERGE_BY_VALUE method is:
moduleVariable.MERGE_BY_VALUE(result, templateName, aggregatorFields[, inhibitorFields])or:
moduleVariable.MERGE_BY_VALUE(result, templateName, aggregatorFields, inhibitorFields[, caseFlag])where:
moduleVariableis the variable corresponding to the module and set withrequire().resultis the object containing the analysis results.templateNameis the template name of the records to merge.aggregatorFieldsis an array corresponding to the fields around which the information is gathered.inhibitorFieldsis an optional array containing one or more fields around which the merge is not applied anymore.caseFlagis an optional boolean that applies the merge considering the case of the first field value around which the information is gathered (see the example below).
For example, given the following template:
TEMPLATE(PERSONAL_DATA)
{
@Name,
@Job,
@Product,
@Company,
@Role
}
and the following extraction rules with the TEXT transformer applied to the Name field:
SCOPE SENTENCE
{
IDENTIFY(PERSONAL_DATA)
{
@Name[TYPE(NPH)]|[TEXT]
<1:5>
@Role[LEMMA("purchaser")]
<1:4>
@Product[KEYWORD("iPhone")]
}
IDENTIFY(PERSONAL_DATA)
{
@Job[LEMMA("software engineer")]
<1:5>
@Company[TYPE(COM)]
<1:4>
@Name[TYPE(NPH)]|[TEXT]
}
}
applied to this text:
JOHN MARKOVITCH is the first purchaser of the new iPhone. The best software engineer for Samsung is John Markovitch.
with this code:
function onFinalize(result) {
mergepost.MERGE_BY_VALUE(result, "PERSONAL_DATA", ["Name"], [], true)
return result;
}
you will get:
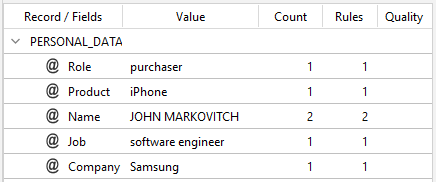
Thanks to the true boolean, the merge is based on the first occurrence of the Name field value JOHN MARKOWITCH written in uppercase.
Note
Even though you don't need the inhibitorFields parameter, you must declare it empty if you need to use the caseFlag parameter.
MERGE_BY_INSTANCE
The MERGE_BY_INSTANCE method merges all the records of a template according to the instance of a value for one or more given fields. Unlike MERGE_BY_VALUE, this allows you to distinguish between identical textual values that do not correspond to the same entity.
The method must be used in the onFinalize function when extraction results are available.
Note
The (optional) use of the SOLITARY attribute is recommended when using this method.
For example, consider this template:
TEMPLATE(PERSONAL_DATA)
{
@Name (S),
@Address,
@Phone
}
With these rules:
SCOPE SENTENCE
{
IDENTIFY(PERSONAL_DATA)
{
@Name[TYPE(NPH) - TYPE(PRO)]
<-9:9>
@Address[TYPE(ADR)]
}
IDENTIFY(PERSONAL_DATA)
{
@Name[TYPE(NPH) - TYPE(PRO)]
<:9>
@Phone[TYPE(PHO)]
}
}
applied to this text:
Steven lives in Baltimora Street and his phone number is 3333333333. His friend Mary bought a house in Tropicana Street where she lives with her husband Steven and his phone number is 3333333331.
you will get:
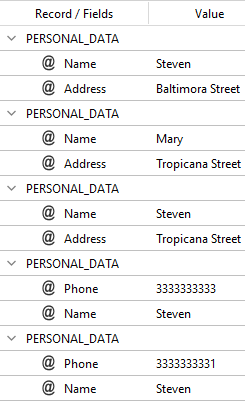
With this code:
function onFinalize(result) {
mergepost.MERGE_BY_INSTANCE(result, "PERSONAL_DATA", ["Name"])
return result;
}
and with this other one:
function onFinalize(result) {
mergepost.MERGE_BY_VALUE(result, "PERSONAL_DATA", ["Name"])
return result;
}
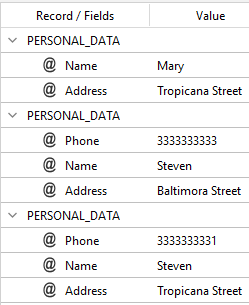
you will get:
| MERGE_BY_INSTANCE | MERGE_BY_VALUE |
|---|---|
 |
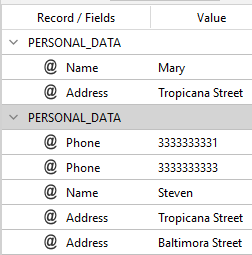 |
As you can see, MERGE_BY_VALUE is based on identical textual values but it does not recognize different entities, while MERGE_BY_INSTANCE allows you to disambiguate between different entities having a common textual value.
The syntax is:
moduleVariable.MERGE_BY_INSTANCE(result, template, aggregatorFields[, inhibitorField])where:
moduleVariableis the variable corresponding to the module and set withrequire().resultis the object containing the analysis results.templateNameis the template name of the records to merge.aggregatorFieldsis an array corresponding to the fields around which the information based on the value instance is gathered.inhibitorFieldis an optional array containing one or more fields around which the merge is not applied anymore.
MERGE_INSTANCE_BEGIN_ONLY
Like MERGE_BY_INSTANCE, with the difference that the MERGE_INSTANCE_BEGIN_ONLY method only considers the beginning of the value instance.
Note
The (optional) use of the SOLITARY attribute is recommended when using this method.
For example, consider this template:
TEMPLATE(PERSONAL_DATA)
{
@Name (S),
@Address,
@Phone
}
With these rules:
SCOPE SENTENCE
{
IDENTIFY(PERSONAL_DATA)
{
@Name[TYPE(NPH) - TYPE(PRO)]
<-9:9>
@Address[TYPE(ADR)]
}
IDENTIFY(PERSONAL_DATA)
{
@Name[TYPE(NPH) - TYPE(PRO)]
<:9>
@Phone[TYPE(PHO)]
}
}
applied to this text:
Steven lives in Baltimora Street and his phone number is 3333333333. His friend Mary bought a house in Tropicana Street where she lives with her husband Steven and his phone number is 3333333331.
you will get:
With this code:
function onFinalize(result) {
mergepost.MERGE_INSTANCE_BEGIN_ONLY(result, "PERSONAL_DATA", ["Name"])
return result;
}
you will get:
The syntax is:
moduleVariable.MERGE_INSTANCE_BEGIN_ONLY_ONLY(result, template, aggregatorFields[, inhibitorField])where:
moduleVariableis the variable corresponding to the module and set withrequire().resultis the object containing the analysis results.templateNameis the template name of the records to merge.aggregatorFieldsis an array corresponding to the fields around which the information based on the value instance beginning is gathered.inhibitorFieldis an optional array containing one or more fields around which the merge is not applied anymore.
REPLACE_FIELD_VALUE
The REPLACE_FIELD_VALUE changes fields values.
It must be used in the onFinalize function when extractions results are available.
Consider the same example used to describe the FIELD_CLONE method, which create a "clone" on an existing field. Then this code:
function onFinalize(result) {
mergepost.FIELD_CLONE(result, "PERSONAL_DATA", "NAME", "NAME_INITIALS");
mergepost.REPLACE_FIELD_VALUE(result, "PERSONAL_DATA", false, "NAME_INITIALS", {"Sherlock Holmes": "S.H.", "John Watson": "J.W."});
return result;
}
creates the clone field and changes its value. The output becomes:
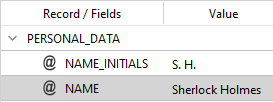
The syntax is:
moduleVariable.REPLACE_FIELD_VALUE(result, template, eraseNotFound, field, replacementRules)where:
moduleVariableis the variable corresponding to the module and set withrequire().resultis the object containing the analysis results.templateis the template name of the records to act upon.eraseNotFoundis a boolean. It can be:- true: all the fields not matching the replacement rules (see below) are deleted from their respective records. If, as a consequence of fields removal, the record becomes empty, also the record is deleted.
- false: all the fields not matching the replacement rules are left untouched.
fieldis the field name.replacementRulesis a JSON object representing replacement rules. Each property name is interpreted as the value to replace, while the property value is the replacement value.
RECORD_CLONE
The RECORD_CLONE method allows you to clone a record with its fields.
For example, consider these two templates:
TEMPLATE(ATHLETES)
{
@FULL_NAME,
@AGE,
@DATE_OF_BIRTH,
@PLACE_OF_BIRTH
}
TEMPLATE(OLYMPIC_CHAMPIONS)
{
@FULL_NAME,
@AGE,
@DATE_OF_BIRTH,
@PLACE_OF_BIRTH
}
If this rule
SCOPE SENTENCE
{
IDENTIFY(ATHLETES)
{
@FULL_NAME[TYPE(NPH)]
<>
@AGE[PATTERN("[1-9][0-9]")]
<>
@DATE_OF_BIRTH[TYPE(DAT)]
<>
@PLACE_OF_BIRTH[SYNCON(100005092)]//@SYN: #100005092# [Baltimore]
}
}
is applied to this text:
Michael Phelps (37) was born on the 30th of June 1985 in Baltimore
you will get:
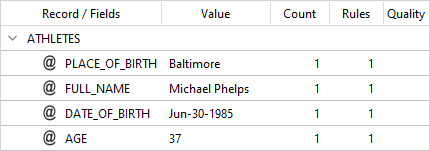
With this code:
function onFinalize(result) {
mergepost.RECORD_CLONE(result, "ATHLETES", "OLYMPIC_CHAMPIONS");
return result
}
you will get:
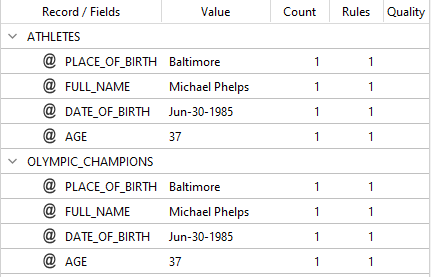
The syntax for RECORD_CLONE is:
moduleVariable.RECORD_CLONE(result, template, newTemplate)where:
moduleVariableis the variable corresponding to the module and set withrequire().resultis the object containing the analysis results.templateis the name of the template on which the clonation is based.newTemplateis the cloned template.
load
The load method prepares one or more of the operations that can be attained with the methods above, but using as its source a configuration file generated when importing a project created with a legacy edition of Studio. Prepared operations are then applied using the apply method.
Warning
The use of the load method is not required in cases other than that indicated above and the import procedure already generates the appropriate statements inside the main.jr file, so there are basically no cases in which you have to write code that uses this method.
For example, when importing an old project, Studio may generate this code:
var mergepost = require("modules/mergepost");
function initialize(cmdline) {
if (!mergepost.load('Config.xml')) {
CONSOLE.error(mergepost.getLastError());
return false;
}
return true;
}
function onFinalize(result) {
result = mergepost.apply(result);
return result;
}
The syntax is:
moduleVariable.load(configPath)where:
moduleVariableis the variable corresponding to the module and set withrequire().configPathis the path of the configuration file generated by the import procedure.
The method returns true in case of success, false otherwise. In case of failure it sets an error message you can retrieve with the getLastError method.
apply
The apply method performs all the operations prepared with the invocation of the load method.
It must be used in the onFinalize function when extractions results are available.
For example:
function onFinalize(result) {
result = mergepost.apply(result);
return result;
}
The syntax is:
moduleVariable.apply(result)where:
moduleVariableis the variable corresponding to the module and set withrequire().resultis the object containing the analysis results.
getLastError
The getLastError method retrieves the message corresponding to the last error that occurred when theload method fails. Use it to display the error message.
For example:
function initialize(cmdline) {
if (!mergepost.load('Config.xml'))) {
CONSOLE.error(mergepost.getLastError());
return false;
}
}
The syntax is:
moduleVariable.getLastError()where moduleVariable is the variable corresponding to the module and set with require().