Positional sequences overview
Introduction
Positional sequence operators allow users to create composite conditions that match two or more disambiguation tokens or atoms based on their reciprocal position and the type of tokens or atoms that are allowed between them.
| Operator | Name | Description |
|---|---|---|
>> |
Strict sequence | The two tokens or atoms matched by the operands on the sides of the operator must be strictly consecutive, no other token or atom is allowed between them |
> |
Loose sequence | The two tokens or atoms matched by the operands on the sides of the operator must be positioned one after the other, but tokens or atoms with low semantic value—adjectives, adverbs, conjunctions, articles, punctuation—are allowed between them |
<> |
Flexible sequence | The two tokens or atoms matched by the operands on the sides of the operator must be positioned one after the other, but any number of tokens or atoms of any type can exist between them within the same sentence |
<< |
Strict sequence with right reference | Equivalent to >>, in the opposite direction, except in the presence of a negated operand |
< |
Loose sequence with right reference | Equivalent to >, in the opposite direction, except in the presence of a negated operand |
Positional sequences can be combined with Boolean operators to create complex conditions.
How sequences work
All types of sequences can act both at the atom or token level of the sentence, according to the attribute after the sequence.
If you use the following attributes:
the distance between the attributes values in the text will be atom-based.
For example, if this rule:
SCOPE SENTENCE
{
DOMAIN(dom1)
{
TYPE(VER)
<1:2>
LEMMA("dog")
}
}
is applied to this text:
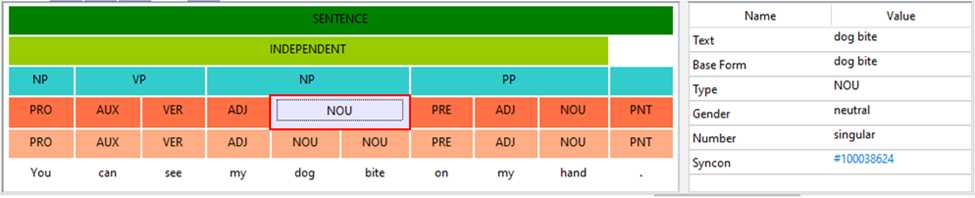
You can see the dog bite on my hand.
you will get no output, because the sequence acts at the token level in the text because of the LEMMA attribute after it, but the lemma in the sentence after the verb is the collocation dog bite, not dog.
Note
In this case, you must consider the sentence at the token level of the Semantic Analysis tool window.
On the other hand, if this rule:
SCOPE SENTENCE
{
DOMAIN(dom1)
{
TYPE(VER)
<1:2>
KEYWORD("dog")
}
}
is applied to the same text above, the rule will trigger on both see and dog, because the sequence acts at the atom level in the text because of the KEYWORD attribute after it, and the required atom after The is dog.
Note
In this case, you must consider the sentence at the atom level of the Semantic Analysis tool window.

Another situation occurs when you apply a scope specification like the following:
SCOPE SENTENCE ON ATOM
{
DOMAIN(dom1)
{
TYPE(VER)
<1:2>
LEMMA("dog")
}
}
If you apply the rule to the same text above:
You can see the dog bite on my hand.
the rule will trigger on both see and dog, because even though the sequence acts at a token level in the text because of the LEMMA attribute after it, the ON ATOM scope specification acts at the atom level of the sentence, prevailing over LEMMA.