normalizepost
Overview
normalizepost is a scripting module providing transformation and normalization features for extraction records.
The available methods for this module are:
FIELD_NORM_STRINGFIELD_NORM_NUMERICRENEXTRAREPLACEFIELDSPLIT_NORM_LIST_REPLACESPLIT_NORM_LIST_REPLACE_REGEXloadapplygetLastErrorclose
When in Studio you install the normalizepost module in your project, Studio modifies the main.jr file to insert this statement at the beginning of the file:
var normalizepost = require("modules/normalizepost");
The statement above sets a variable with an instance of the module so that you can use it inside event handling functions.
normalizepost has to be invoked in the onFinalize function, where extraction results are available.
FIELD_NORM_STRING
Purpose and syntax
FIELD_NORM_STRING normalizes fields values in various ways.
The syntax is:
moduleVariable.FIELD_NORM_STRING(result, templateName, fieldName, normalizationType, normalizationRules)where:
moduleVariableis the variable corresponding to the module and set withrequire().resultis the object containing the analysis results.templateNameis the template name of the records to act upon. It can be an asterisk (*), which means "any template".fieldNameis the field name.-
normalizationTypeis the normalization type. It's a string that can be:- CASE
- BOOL
- REPLACE
- REPLACE_REGEX
- REPLACE_REGEX_DEBUG_MODE
Normalization types are described below.
-
normalizationRulesis the specification of the normalization and its possible values vary based on the value ofnormalizationtype(see below).
Normalization types and formats
CASE
CASE normalization applies a specific letter case to field values.
Parameter normalizationRules must be a string with one of these values:
- UCASE: all words are uppercased
- LCASE: all words are lowercased
- TCASE: simplified title case, all words are capitalized
For example, this code:
function onFinalize(result) {
normalizepost.FIELD_NORM_STRING(result, "PERSONAL_DATA", "NAME", "CASE", "TCASE");
return result;
}
capitalizes all the words in the value of each occurrence of field NAME in all the PRESONAL_DATA template records.
BOOL
BOOL normalization replaces values like yes and no with alternative text.
If the alternative text is empty, the field is deleted. If, as consequence of the replacement with empty strings, all of a record's fields are deleted, the entire record is deleted too.
Parameter normalizationRules must be a string with this syntax:
alternativeForYes\\alternativeForNowhere alternativeForYes is the replacement for "yes" values and alternativeForNo is the replacement for "no" values.
For example, this code:
function onFinalize(result) {
normalizepost.FIELD_NORM_STRING(result, "*", "Answer", "BOOL", "TRUE\\FALSE");
return result;
}
changes all "yes" values to TRUE and all "no" values to FALSE for all the instances of field Answer occurring in any record of any template.
The method recognizes "yes" and "no" values written in English, Spanish, French, German and Italian, no matter which the language of the analysis project is.
REPLACE
REPLACE normalization replaces a given field value with another.
If the replacement text is empty, the field is deleted. If, as consequence of replacement with empty strings, all of a record's fields are deleted, the entire record is deleted too.
Parameter normalizationRules can be:
-
An object with this structure:
{ valueToReplace: newValue }where
valueToReplaceis the value to replace. Its value must be in lower case and the match between it and the fields' values is case insensitive andnewValueis the replacement value.
Or:
- The name of a variable set with
SPLIT_NORM_LIST_REPLACE.
For example, this code:
function onFinalize(result) {
normalizepost.FIELD_NORM_STRING(result, "PERSONAL_DATA", "Job", "REPLACE", {"software engineer": "programmer"});
return result;
}
replaces with programmer all the occurrences of software engineer, regardless of the letter case, for the Job field in all the PERSONAL_DATA template records.
REPLACE_REGEX
REPLACE_REGEX normalization replaces any occurrence of a given JavaScript regular expression with an alternative text which can possibly contain reference to capturing groups like $1, $2, etc.
If the replacement text is empty, the field is deleted. If, as consequence of replacement with empty strings, all of a record's fields are deleted, the entire record is deleted too.
Parameter normalizationRules can be:
-
An array of objects object with this structure:
{ regexp: regularExpression, value: replacementText }where
regularExpressionis the JavaScript regular expression used to find the text to replace andreplacementTextis the replacement text.
Or:
- The name of a variable set with
SPLIT_NORM_LIST_REPLACE_REGEX
For example, this code:
function onFinalize(result) {
normalizepost.FIELD_NORM_STRING(result, "CRIMINAL", "FaceFeature", "REPLACE_REGEX", [{"regexp": /(?:great|big|large) (.*)/, "value": "$1: large"}, {"regexp": /(?:small|little|tiny|) (.*)/, "value": "$1: small"}]);
return result;
}
replaces expressions like big nose or small ears with nose: large and ears: small in the FaceFeature field values of CRIMINAL template records.
REPLACE_REGEX_DEBUG_MODE
REPLACE_REGEX_DEBUG_MODE acts like REPLACE_REGEX but it also activates a debug mode to check if your regular expressions are working.
This code:
function onFinalize(result) {
normalizepost.FIELD_NORM_STRING(result, "CRIMINAL", "FaceFeature", "REPLACE_REGEX_DEBUG_MODE", [{"regexp": /(?:great|big|large) (.*)/, "value": "$1: large"}, {"regexp": /(?:small|little|tiny|) (.*)/, "value": "$1: small"}]);
return result;
}
replaces expressions like big nose or small ears with nose: large and ears: small in the FaceFeature field values of CRIMINAL template records. You can see notifications about your regular expressions from the Console tool window:

You can also activate this mode using REPLACE_REGEX but adding a string after the normalizationRules parameter, like this:
function onFinalize(result) {
normalizepost.FIELD_NORM_STRING(result, "CRIMINAL", "FaceFeature", "REPLACE_REGEX", [{"regexp": /(?:great|big|large) (.*)/, "value": "$1: large"}, {"regexp": /(?:small|little|tiny|) (.*)/, "value": "$1: small"}], "debug mode");
return result;
}
This string can be:
trueordebug mode: specify all strings transformed by the regular expressions.verbose debug mode: specify all strings transformed and untransformed by the regular expressions.
FIELD_NORM_NUMERIC
The FIELD_NORM_NUMERIC method converts numbers written in words into numbers expressed in digits, possibly applying a multiplication factor to the numbers obtained.
Consider for example this template:
TEMPLATE(DISTANCE)
{
@KILOMETERS,
@METERS
}
If the following rule:
SCOPE SENTENCE
{
IDENTIFY(DISTANCE)
{
LEMMA("distance")
<1:4>
KEYWORD("a")
<1:4>
KEYWORD("b")
<1:3>
LEMMA("be")
<1:3>
@METERS[KEYWORD("five thousand")]
}
}
is applied to this input text
The distance from A to B is five thousand m.
with this code (see also the FIELD_CLONE method of mergepost):
function onFinalize(result) {
mergepost.FIELD_CLONE(result, "DISTANCE", "METERS", "KILOMETERS");
return result
}
you get:
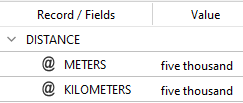
If you change the code like this:
function onFinalize(result) {
mergepost.FIELD_CLONE(result, "DISTANCE", "METERS", "KILOMETERS");
normalizepost.FIELD_NORM_NUMERIC(result, "EN", "DISTANCE", "KILOMETERS", "*m");
return result
}
and apply the rule above to the same input text, you get:
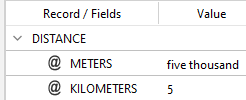
The number in words has been converted to digits, then the multiplying factor *m, where the "m" stands for "milli", corresponding to x 10^-3, is applied.
If the field value is already a number expressed with digits, no conversion takes place, but the number is recognized as such and the possible multiplication factor is applied.
So, in the case of the example above, if the initial value of field KILOMETERS had been 5000, it would have become 5 all the same.
The syntax is:
moduleVariable.FIELD_NORM_NUMERIC(result, lang, templateName, fieldName, adapt)where:
moduleVariableis the variable corresponding to the module and set withrequire().resultis the object containing the analysis results.langrefers to the language in which numbers in words are written. Possible values are:- EN for English
- IT for Italian
- ES for Spanish
- DE for German
- NL for Dutch
templateNameis the template name of the records to act upon. It can be an asterisk (*), which means "any template".fieldNameis the field name.-
adaptis a multiplication factor. It can be an empty string, in which case the numeric value is not altered, or it can be one the following:Value Multiplication factor *p (pico) x 10-12 *n (nano) x 10-9 *u (micro) x 10-6 *m (milli) x 10-3 *K (kilo) x 103 *M (mega) x 106 *G (giga) x 109 *T (tera) x 1012
RENEXTRA
The RENEXTRA method renames records' templates and fields.
Consider for example this template:
TEMPLATE(PERSONAL_DATA)
{
@NAME,
@ADDRESS,
@JOB,
@AGE
}
If the following rule:
SCOPE SENTENCE
{
IDENTIFY(PERSONAL_DATA)
{
@NAME[TYPE(NPH)]
<>
@AGE[PATTERN("[1-9][0-9]")]
<>
@JOB[LEMMA("technical writer")]
}
}
is applied to this input text:
Christine is 42 years old and works as a technical writer.
you get this output:
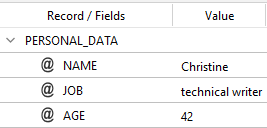
With this code:
function onFinalize(result) {
normalizepost.RENEXTRA(result, "PERSONAL_DATA", "PERSONAL_INFORMATION", null);
return result;
}
if the rule above is applied to the same input text, you get:
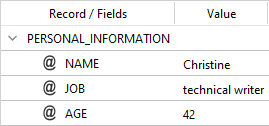
The template name for PERSONAL_DATA records has changed to PERSONAL_INFORMATION
If the code was:
function onFinalize(result) {
normalizepost.RENEXTRA(result, "PERSONAL_DATA", null, [{name: "NAME", new: "PROPER_NAME"}, {name: "AGE", new: "YEARS_OF_AGE"}]);
return result;
}
the output would be:
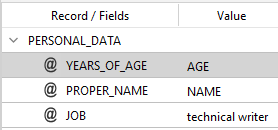
In this case, fields have been renamed and the old names have become the values of the fields themselves.
Note
Odd as may seem, this behavior is by design. In fact, this method replicates the behavior of a post-processor that was available in the legacy technology of which Studio represents the evolution and is meant to be used for backward compatibility when importing old projects. For an alternative way to rename records' templates and fields, consider the JsonPlug module.
RENEXTRA is typically used in combination with REPLACEFIELD (see below).
The syntax is:
moduleVariable.RENEXTRA(result, templateName, newTemplateName, renameRules)where:
moduleVariableis the variable corresponding to the module and set withrequire().resultis the object containing the analysis results.templateNameis the template name of the records to act upon. It can be an asterisk (*), which means "any template".newTemplateNameis the new template name that will replace the old one. Ifnull, the template name is not changed, so usenullif you only want to rename fields.-
renameRulesis an array containing objects each representing a field rename rule and having the following properties:name: old field name.new: new field name.
If
null, fields are not renamed, so usenullif you only want to change the template name.
REPLACEFIELD
The REPLACEFIELD method changes all the matches of a regular expression inside the values of all the fields that have been renamed using the RENEXTRA method.
Consider this template:
TEMPLATE(PERSONAL_DATA)
{
@Name,
@Job,
@Product,
@Company,
@Role
}
If the following rule:
SCOPE SENTENCE
{
IDENTIFY(PERSONAL_DATA)
{
@Name[TYPE(NPH)]
<1:5>
@Job[LEMMA("software engineer")]
<1:4>
@Company[TYPE(COM)]
}
}
is applied to this input text:
George Dickinson is a software engineer for Acme Ltd.
you will normally get:
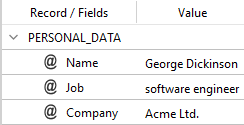
With this code:
function onFinalize(result) {
var renameRules = [{name: "Name", new: "PseudoName"}]
normalizepost.RENEXTRA(result, "PERSONAL_DATA", null, renameRules);
normalizepost.REPLACEFIELD(result, "Name", "John Doe");
return result;
}
it becomes:
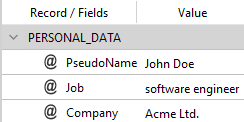
The syntax is:
moduleVariable.REPLACEFIELD(result, regularExpression, replacementString)where:
moduleVariableis the variable corresponding to the module and set withrequire().resultis the object containing the analysis results.regularExpressionis a string containing a regular expression used to find the parts of fields' value to change.replacementStringis the string that replaces all the matches ofregularexpressionin fields' values.
SPLIT_NORM_LIST_REPLACE
Use the SPLIT_NORM_LIST_REPLACE method in combination with the REPLACE normalization type to create list files of replacement—and new—values.
Warning
List files must be created in a new sub-folder under the rules folder, called normalizepost.
Set a variable with an instance of the method so that you can use it inside the onFinalize function (see code below).
For example, consider this template:
TEMPLATE(PERSONAL_DATA)
{
@Name,
@Address,
@Phone,
@Job
}
If this rule:
SCOPE SENTENCE
{
IDENTIFY(PERSONAL_DATA)
{
@Name[TYPE(NPH)]
<>
@Job[LEMMA("software engineer")]
}
}
is applied to this text:
John is a software engineer.
you will get:
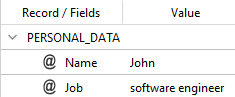
With this code:
function onFinalize(result) {
var replacementList = normalizepost.SPLIT_NORM_LIST_REPLACE("replacements.cl")
normalizepost.FIELD_NORM_STRING(result, "PERSONAL_DATA", "Job", "REPLACE", replacementList);
return result;
}
and with the list file compiled in this way:
programmer=software engineer|developer|dev
you will get:
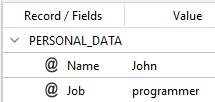
The syntax of SPLIT_NORM_LIST_REPLACE is:
moduleVariable.SPLIT_NORM_LIST_REPLACE(listFileName)where:
moduleVariableis the variable corresponding to the module and set withrequire().listFileNameis the list file name.
The syntax for compiling a list file is:
newValue=valueToReplace_1|valueToReplace_2[|valueToReplace_3...]where:
newValueis the new value.valueToReplace_nis the value to replace.
If newValue is empty, the field is deleted. If, as consequence of replacement with empty strings, all of a record's fields are deleted, the entire record is deleted too.
SPLIT_NORM_LIST_REPLACE_REGEX
Like SPLIT_NORM_LIST_REPLACE with the difference that list files are compiled with JavaScript regular expressions and the SPLIT_NORM_LIST_REPLACE_REGEX method is combined with the REPLACE_REGEX normalization type.
For example, consider this template:
TEMPLATE(PERSONAL_DATA)
{
@Name,
@Address,
@Phone,
@Job
}
If this rule:
SCOPE SENTENCE
{
IDENTIFY(PERSONAL_DATA)
{
@Name[TYPE(NPH)]
<>
@Job[LEMMA("software developer")]
}
}
is applied to this text:
John is a software developer.
you will get:
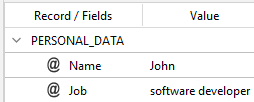
With this code:
function onFinalize(result) {
var replacementList = normalizepost.SPLIT_NORM_LIST_REPLACE_REGEX("replacements.cl")
normalizepost.FIELD_NORM_STRING(result, "PERSONAL_DATA", "Job", "REPLACE_REGEX", replacementList);
return result;
}
and with the list file compiled in this way:
$2 programmer=\b((software) developer)\b/i
Warning
List files must be created in a new sub-folder under the rules folder, called normalizepost.
you will get:
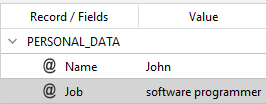
The syntax of SPLIT_NORM_LIST_REPLACE_REGEX is:
moduleVariable.SPLIT_NORM_LIST_REPLACE_REGEX(listFileName)where:
moduleVariableis the variable corresponding to the module and set withrequire().listFileNameis the list file name.
The syntax for compiling a list file is:
replacementString=regularExpressionwhere:
replacementStringis the replacement string which can possibly contain reference to capturing groups like $1, $2, etc.regularExpressionis the JavaScript regular expression.
If replacementString is empty, the field is deleted. If, as consequence of replacement with empty strings, all of a record's fields are deleted, the entire record is deleted too.
load
The load method prepares one or more of the operations that can be attained with the methods above, but using as its source a configuration file generated when importing a project created with a legacy edition of Studio. Prepared operations are then applied using the apply method.
Warning
The use of the load method is not required in cases other than that indicated above and the import procedure already generates the appropriate statements inside the main.jr file, so there are basically no cases in which you have to write code that uses this method.
For example, when importing an old project, Studio may generate this code:
function initialize(cmdline) {
if (!normalizepost.load('Config.xml')) {
CONSOLE.error(normalizepost.getLastError());
return false;
}
return true;
}
function onFinalize(result) {
result = normalizepost.apply(result);
return result;
}
Its syntax is:
moduleVariable.load(configPath)where:
moduleVariableis the variable corresponding to the module and set withrequire().configPathis theconfig.xmlfile path generated by the import procedure.
The method returns true in case of success, false otherwise. In case of failure it sets an error message you can retrieve with the getLastError method.
apply
The apply method performs all the operations prepared with the invocation of the load method.
For example:
function onFinalize(result) {
result = normalizepost.apply(result);
return result;
}
The syntax is:
moduleVariable.apply(result)where:
moduleVariableis the variable corresponding to the module and set withrequire().resultis the object containing the analysis results.
getLastError
The getLastError method retrieves the message corresponding to the last error that occurred when theload method fails. Use it to display the error message.
For example:
function initialize(cmdline) {
if (!normalizepost.load('Config.xml'))) {
CONSOLE.error(normalizepost.getLastError());
return false;
}
}
The syntax is:
moduleVariable.getLastError()where moduleVariable is the variable corresponding to the module and set with require().
close
The close method is used to free up the resources allocated by the normalizePost module object.
It's not mandatory to invoke this method, but if you decide to do it, invoke it inside the shutdown function.
For example:
function shutdown() {
normalizepost.close();
}
The syntax is:
moduleVariable.close()
where moduleVariable is the variable corresponding to the module and set with require().