Combined use of transformation and composition
Introduction
In extraction rule writing, transformation and composition options can be used in combination to reach a desired normalized output.
The syntax to combine transformation and composition is the following:
SCOPE scopeOption
{
IDENTIFY(templateName)
{
@field[attribute]|[transformation composition]
}
}where:
-
transformationrefers to one of the transformation options listed below: -
compositionrefers to a pound sign (#) followed by a whole number. For example:
SCOPE scopeOption
{
IDENTIFY(templateName)
{
@field1[attribute1][transformation#1]
sequenceOperator
@field1[attribute2]|[transformation#2]
}
}Transformation and composition options must be typed in uppercase and in the order indicated above, with no spaces between the two. The two syntaxes are written between brackets and positioned at the end of a full and correct extraction rule; a vertical bar (called pipe, |) separates the rule and the transformation/composition part. For composition, numbering within each rule should start with the number one (1), without any gap in the sequence. Each so-called sequence "chunk" (#1, #2, etc.) shares the same destination field and is part of a sequence. The number associated to each chunk represents the position that the extracted value will assume in the final output.
When using this option, even in combination with transformation, it is not necessary to use the extraction syntax on every element of the sequence; in other words, the user can choose which elements will be part of the extraction and which elements will act only as constraints in the rule.
Consider the following example:
SCOPE SENTENCE
{
IDENTIFY(CYBERCRIME)
{
@Event[ANCESTOR(100220)]|[ENTRY#2]// 100220: website, web-site,
<1:3>
@Event[LEMMA("hack") + TYPE(VER)]|[BASE#1]
}
IDENTIFY(CYBERCRIME)
{
@Event[LEMMA("hack") + TYPE(VER)]|[BASE#1]
<1:4>
@Event[ANCESTOR(100220)]|[ENTRY#2]// 100220: website, web-site
}
}
These two rules are meant to extract strings indicating the hacking of websites. The two rules look for the verb to hack (lemma hack, + TYPE (VER)) either preceded (first rule) or followed (second rule, <1:3> and <1:4>, see positional sequences) by the chain of concepts starting from the syncon website (ANCESTOR(100220)). This means that both active (hack a site) and passive voices (a site has been hacked) mentioning the same concepts will be recognized. Please note that the attributes enclosed in the extraction syntax extract different values for the same field @Event and that the composition syntax is applied to each. The #1 and #2 declarations determine the following behavior: every element extracted for the attribute marked with #1 will be the first element to compose the final output; every element extracted for the attribute marked with #2 will be the second element to compose the final output. Transformation options are applied which return the base form for the verb and the entry for the Ancestor.
Consider the extraction output if the rule above is run against the following sample text:
Culture Ministry website hacked
Published: 16 Jan 2013 at 11.23 Online news: Local News
The Culture Ministry's Thai website has been hacked by a group demanding the ministry return the banned political soap opera "Nua Mek 2" to the public.
The hackers, who called themselves "The Bad Piggies Team", posted a "Nua Mek 2" banner and two messages: "Return Nua Mek 2 to Us" and "HACKED by THE BAD PIGGIES TEAM" showing intermittently with a cartoon avatar of a green pig head.
They were posted on Wednesday morning. The website was shut down shortly afterwards.
The ministry's website in English was not hacked.
(story continues below)
The Bad Piggies Team hacked the Culture Ministry's website on Jan 16, 2013.
The text contains three strings matching the rules above:
- Culture Ministry website hacked
- website has been hacked
- hacked the Culture Ministry's website
The first two (passive voices) are matched by the first rule, while the last instance (active voice) is matched by the second.
Transformation option BASE transforms hacked into the lemma's base form hack. The option ENTRY transforms every instance of the concept website into the main lemma's base form. This also occurs for the string Culture Ministry website, which is disambiguated as a proper noun, unknown to the Knowledge Graph, but virtually recognized as a child of the concept website (its virtual supernomen). Since virtual concepts do not have an entry form, then the entry of their virtual supernomen is chosen; in this case it is the lemma website. Finally, the composition syntax allows the lemma hack to always be the first element in the final output (chunk #1) and the ancestor website to always be the second (chunk #2). This occurs independently from their actual position in the text. This entire process results in a final normalized output of one single record, hack website, for three originally different instances of the same concept.
Transformation, scripting and composition
Transformation options and composition can be combined with the SCRIPT transformation option.
The syntax is:
SCOPE scopeOption
{
IDENTIFY(templateName)
{
@field1[attribute1][transformation + SCRIPT("functionName")#1]
sequenceOperator
@field1[attribute2]|[transformation + SCRIPT("functionName")#2]
...
}
}If this rule, aimed at extracting people's jobs:
SCOPE SENTENCE
{
IDENTIFY(PERSONAL_DATA)
{
@Job[LEMMA("product")]|[BASE + SCRIPT("toLower")#1]
<1:2>
@Job[KEYWORD("developers")]|[BASE + SCRIPT("toLower")#2]
}
}
is applied to this input text:
DAVID AND ANTHONY ARE THE TWO PRODUCT DEVELOPERS.
you will get:
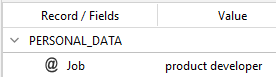
As you can see, the textual value PRODUCT DEVELOPERS was turned into its base form with BASE and into lowercase with the toLower scripting function.