Input for model blocks
First level keys
The top-level keys that can be present in the JSON input to a block model depend on whether NL Core is used by the block and on the version of that component.
If NL Core is present, as is the case with Knowledge Models../knowledge-models/index.md), basic mode ML models and symbolic models, the block recognizes some combinations of keys in a mutually exclusive way: if some keys exist, the others cannot exist. Valid combinations are shown in this article and include one or more of these keys:
text(string)sections(array)sectionsText(object)documentLayout(object)options(object)
If the block uses NL Core version 4.12 or later, it can also recognizes this key:
documentData(array)
Tip
You can determine the version of NL Core for a symbolic model by selecting Show resources  in the editor or looking at the Resources area after selecting the model in the Models view of the dashboard.
in the editor or looking at the Resources area after selecting the model in the Models view of the dashboard.
In general, a block using NL Core expects a text to analyze. The top level keys containing text are text, sectionsText and documentLayout, so one of them is mandatory, while the other keys are optional. Di nuovo, le combinazioni vaide sono elencate sotto.
Advanced mode ML models don't use NL Core and the only input key they recognize is:
document(object)
In this case the block doesn't expect a text to analyze: instead it expects text features, that is the outcome of the NLU analysis of a text.
text
text is text that must be analyzed by NL Core.
When input mapping is needed, this key is typically mapped, through the corresponding text input property, to:
- The
modelName.document.contentkey of another model block. - The
contentkey of a TikaTesseract Converter processor or a URL Converter processor block.
text is alternative to documentLayout: if one of these keys is present in input, the other must be omitted.
text can be complemented by sections and sectionsText for Studio-generated symbolic models whose rules can distinguish between text sections.
documentLayout
documentLayout is an object with the same structure of the result key of Extract Converter processor output, so a model using it is typically preceded by an Extract Converter block and this key is mapped through the corresponding documentLayout input property to that output key.
It must be used for Studio-generated symbolic models with rules that leverage layout information and for extraction ML models trained with layout-based annotations.
Note
Any model with NL Core recognizes this key and is able to derive plain text to analyze from it, but there is no point in passing layout information to a model that is not specialized to leverage it.
If documentLayout is present in the input JSON, text, sections and sectionsText—which are alternative means of giving input text to the block—must be omitted.
sections
The sections key is optional and complementary to text. When present, it indicates the boundaries of text sections, for example:
"sections": [
{
"name": "TITLE",
"start": 0,
"end": 61
},
{
"name": "BODY",
"start": 62,
"end": 2407
}
]
Currently only symbolic models designed with Studio can contain hand-written symbolic rules that account for sections. In particular, with multiple sections, rules can be written that are triggered only by the text of a given section, while Platform generated rules have all the same scope—even if the input document has sections—that is the entire input text.
sections is an array. Each item corresponds to a section and it's an object with these properties:
name(string): section name.start(integer): zero-based position of the first character in the section inside the value oftext.end(integer): zero-based position of the first character after the section inside the value oftext.
If input mapping is needed, the expected mapping of the corresponding sections input property is mapped to a key of the workflow input or the modelName.document.sections property of an upstream model block which in turn received sections data.
sectionsText
The sectionsText key is text to be analyzed divided into sections, for example:
"sectionsText": [
{
"name": "TITLE",
"text": "This is a title"
},
{
"name": "BODY",
"text": "This is the body"
}
]
sectionsText is an array of objects. Each object has these properties:
name(string): section nametext(string): section text
The model builds plain text to analyze by concatenating the values of the text properties of the array items using a newline character as a separator.
If the text key is also set, the text obtained from sectionsText is appended to the one represented by text using a newline character as a separator, so the model receives a text that is the result of the concatenation of two texts. The model also receives automatically computed section boundaries referred to the concatenated text.
For example:
-
Value of
text:We shall pay any price, bear any burden, meet any hardship, support any friend, oppose any foe to assure the survival and success of liberty. -
Value of
sectionsText:[ { "name": "TITLE", "text": "President John F. Kennedy delivered his inaugural address" } ] -
Concatenated plain text:
We shall pay any price, bear any burden, meet any hardship, support any friend, oppose any foe to assure the survival and success of liberty. President John F. Kennedy delivered his inaugural address -
Sections boundaries:
- Section name:
TITLE - Start: 142
- End: 199
- Section name:
When input mapping is needed, the corresponding sectionsText input property is mapped to one key of the workflow input or to the modelName.document.sectionsText property of a model block which in turn received that data.
options
Theoptions object contains optional parameters that can be passed to the model to influence its behavior. They affect NL Core.
The most extensive structure that this object can have is this:
"allCategories": boolean,
"custom": object,
"disambiguation": {
"flags": number
},
"output": object,
"rules": object
or, for old models, this:
"allCategories": boolean,
"custom": object
Old models have NL Core version 4.11 or lower.
Tip
You can determine the version of NL Core for a symbolic model by selecting Show resources in the editor or looking at the Resources area after selecting the model in the Models view of the dashboard. For basic mode ML models, the version of NL Core is tied to that of the ML engine, which is visible when you select the model from the list.
All the components of this structure are optional; they are described below.
allCategories
Retained for backwards compatibility, this option is equivalent to the allCategories property of the rules object.
custom
Retained for backwards compatibility, this option is equivalent to the customOptions property of the rules object.
disambiguation
This is an advanced option for NL Core.
It is meant to be used with the support of your expert.ai technical contact should he determine that the tuning of low-level options can improve the quality of NLU analysis.
When used, this option contains, in its only flags parameter, a number representing one or more disambiguation options. Multiple options are combined in binary OR.
output
The most extensive structure that this object can have is the following:
"output": {
"analysis": string array,
"features": string array,
"knowledgeProperties": string array
}All the components of this structure are optional.
These options affect the output of NL Core. The properties specified for this object override the values of corresponding functional properties of the model block. These are the correspondences:
-
analysisarray items:The presence of items in the
analysisarray is equivalent to turn on corresponding functional properties in the model block, the absence is equivalent to turn them off.Item value Functional property relevants Output relevants sentiment Output sentiment relations Output relations segments Output segments Functional property Apply rules corresponds to two items, categories and extractions. If all you want are categorization results, specify only categories, while if you just want information extraction specify only extractions.
-
featuresarray items:The presence of an item in the
featuresarray is equivalent to turn on the corresponding functional property in the model block, the absence is equivalent to turn it off.Item value Functional property syncpos Synchronize positions to original text dependency Output dependency tree knowledge Output knowledge externalIds Output external ids extradata Output rules extra data explanations Output explanations namespaces Output namespace metadata documentData Output document data layout Output layout information -
knowledgePropertiesarray: this array replaces the value of the Required user properties for syncons functional property.
If the analysis array is empty, the model still performs document analysis, named entity recognition and keyphrase extraction with NL Core, producing output keys content, entities, language, mainLemmas, mainPhrases, mainSentences, mainSyncons, options, paragraphs, phrases, sentences, tokens, topics and version.
rules
The most extensive structure that this object can have is the following:
"rules": {
"allCategories": boolean,
"applyRules": boolean,
"customOptions": object,
"namespace": string
}All the components of this structure are optional; they are described below.
allCategories
When its value is false, a categorization model returns only the categories with the highest scores, that is those with the winner property set to true. The default value is true.
applyRules
The value of this option overrides that of the Apply rules functional property.
customOptions
This object can be used to convey custom options to Studio-generated symbolic models and thesaurus models that access them via specific JavaScript code.
Thesaurus scoring algorithms configuration
Thesaurus models are based on NL Core and contain automatically generated JavaScript code which implements alternative scoring algorithms that can affect the confidence score of the extractions of thesaurus concepts. The JavaScript can also affect extraction scoring in general using thresholds and section boosts.
The scoring algorithms are based on configuration settings which can be changed with the following properties of customOptions:
scoreConfigadvancedScoreConfiglibraryScoreConfigscorePostProcessingConfig
The properties correspond to object variables defined inside the JavaScript. By specifying one or more of the above objects in the input JSON you can override the default values of the properties of those variables which were set during model generation.
The scoreConfig object contains configuration settings for the thesaurus-based scoring algorithm, which is based on labels and relationships between concepts. It must be set like this (here with default values):
"scoreConfig": {
"disableScore": false,
"defaultScore": 1,
"normalize": 100,
"boostByHierarchy": {
"byParent": 1,
"byChildren": 0.5,
"byRelated": 0.3
},
"boostByFrequency": true,
"boostByLabel": {
"matchPrefLabel": 1,
"matchAltLabel": 0.5,
"lengthMeasure": 0.1,
"ignoreCase": true
}
}
where:
disableScore(boolean): if true, the algorithm is not used.defaultScore(number): default base score for all extractions. Ignored ifboostByFrequencyis true.normalize(number): the final score of extraction will be normalized to a value in the range between 0 and the value of this parameter. Use value 0 to disable score normalization.-
boostByHierarchy(object): its properties are multiplication factors that are applied to the base score based on the relationship between the extracted concept and other concepts in the thesaurus.byParent(number): applied for every broader concept that is also extracted from the text. Value 0 is interpreted as no multiplication.byChildren(number): applied for every narrower concept that is also extracted from the text. Value 0 is interpreted as no multiplication.byRelated(number): applied for every non-hierarchically related concept that is also extracted from the text. Value 0 is interpreted as no multiplication.
-
boostByFrequency(boolean): when true, the base score is the concept frequency in the text. -
boostByLabel(object): its properties determine how the base score is affected by the relationship between the extracted text and the concept labels.matchPrefLabel(number): multiplication factor applied to the base score if the matching text is the preferred label.matchAltLabel(number): multiplication factor applied to the base score if the matching text is one of alternative labels.lengthMeasure(number): multiplication factor applied to the base score that is further multiplied by the number of tokens—separated by space—of the match.ignoreCase(boolean): when true, the case is ignored when matching the text and the labels of the concept.
The advancedScoreConfig object contains configuration settings for the document-based scoring algorithm, which is based on the frequency and the position of the mentions of the concepts in the text. It must be set like this (here with default values):
"advancedScoreConfig": {
"disableAdvancedScore": false,
"parameters": {
"k": 0.5,
"b": 0.5,
"avgE": 1.0,
"posB": 0.25
}
}
The formula used by the algorithm is:
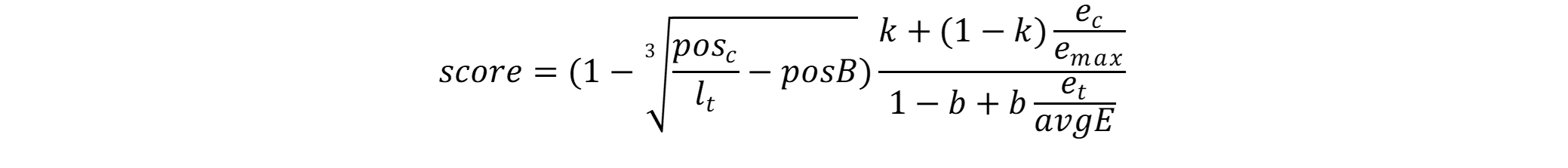
where:
poscis the zero-based start position in the text of the extraction.ltis the length of the text in characters.posBis a parameter (see below).kis a parameter (see below).ecis the number of extraction for the concept.emaxis the number of mentions of the concept that has more extractions.bis a parameter (see below).etis the total number of extractions.
The properties of the advancedScoreConfig object are:
disableAdvancedScore(boolean): if true, the algorithm is not used.-
parameters(object): its properties are tuning parameters for the score.k(number): positive tuning parameter to normalize the frequency of the concept in the text. Value between 0 and 1, where 0 means pure relative frequency.b(number): positive tuning parameter that determines the scaling by text length. Value between 0 and 1, where 1 corresponds to fully scaling the concept weight by the text length, and 0 corresponds to no length normalization.avgE(number): average number of extractions per document in a reference corpus. Number greater than 0.posB(number): position bias. It boosts the score of extractions occurring within the initialposBpercent of the text. Number between 0 and 1.
The libraryScoreConfig object contains configuration settings for an algorithm based on TF-IDF.
It must be set like this (here with default values):
"libraryScoreConfig" : {
"disableLibraryScore" : false,
"idf" : {...}
};
where:
disableLibraryScore(boolean): if true, the algorithm is not used.idf(object): pre-computed inverse document frequencies for terms. Each property of the object is a term and the value of the property is the inverse document frequency. For example:
{"investment":5.2,"interest":8.7,"stock":3.4,"dividend":6.1,"portfolio":9.3,"asset allocation":2.9,"equity":7.5,"capital gains":4.6,"bond":8.2,"liquidity":2.3,"mutual fund":6.7,"market value":5.8,"fixed income":3.1,"risk management":9.6,"hedge fund":7.3,"credit rating":4.9,"financial planner":6.5,"pension":3.8,"retirement account":8.9,"401(k)":5.6,"debt":2.7,"budget":9.2,"savings account":4.3,"tax deduction":7.9,"inflation":3.6,"insurance":9.1,"credit score":2.4,"real estate":8.4,"net worth":6.3,"cash flow":5.5,"economic indicators":4.7,"asset management":7.7,"leverage":3.9,"dollar cost averaging":8.6,"compound interest":6.9,"credit card":2.8,"recession":9.7,"solvency":5.9,"taxable income":4.2,"bankruptcy":7.2 ...}
The scorePostProcessingConfig object contains general score thresholds and section-based boost values. It is defined like this (with default values):
"scorePostProcessingConfig": {
"cutThresholds": {
"cutByScore": 0.0,
"cutByChildrenScore": 0.0
},
"sectionsBoost": {
"TITLE": 3,
"BODY": 1
}
}
where:
-
cutThresholds(object): its properties may determine the removal of concept extractions if their score does not reach a specified threshold.cutByScore(number): extractions with a confidence score lower than this are cut from the output of the model. Value 0 means no cut.cutByChildrenScore(number): extractions are cut from the output if also descendant concepts are extracted and their score is higher than this threshold. Value 0 means no cut.
-
sectionsBoost(object): if the model has configured sections, this parameter allows boosting the confidence score of extractions based on the section in which the mentions of concepts were found.
Its properties have a name corresponding to the name of a section and a numeric value which is used as a multiplication factor applied to the confidence score of any extraction due to some text in the section. Value 1 means no boost.
The default value above is for a model with TITLE and BODY sections.
normalizeToConceptId
The normalizeToConceptId property of the customOptions object is a boolean that, when true, makes a thesaurus model add to its output extra data containing additional thesaurus information for extracted concepts.
namespace
The value of this option overrides that of the Rules output namespace functional property.
documentData
The documentData input key is optional and, when present, contains side-by-side information about the document that can be used by a symbolic model.
It is an array, each item of which represents one piece of information.
The type of information is indicated by the mandatory type property:
disambiguation: a text token or a disambiguation which, for the text ranges indicated bypositions(see below), overwrites the choices made by the model's text analysis.entity: reserved for future use.tag: a tag instance which, in the positions indicated bypositions(see below), is added to any other tag instances that a CPK developed with Studio can produce via tagging rules or JavaScript and that the same CPK can exploit in categorization or extraction rules. More information about tag levels in the dedicated documentation. The tag instance seats on level 0.annotation: reserved for future use.
If type is disambiguation, the item also has a disambiguationOptions object property.
The disambiguationOptions object has a mandatory property type which can be either token or semantic. If it's token, it's also the only property of the object and means that positions contains the ranges on one or more tokens that are alternative to those the the text analysis would find when tokenizing the text.
If type is semantic, instead, the remaining properties of the disambiguationOptions object specify an alternative disambiguation for the text ranges indicated in positions. These properties are:
baseForm(string): base form, that is the lemmaentityId(integer): a numeric ID of choice, used to identify anydocumentDatadisambiguation item referred to the same named entityextraData: reserved for future useparentSyncon(integer): identification number of the "parent" syncon in the Knowledge Graph
If type is tag, the item also has a tagOptions object property which in turn has these properties:
tag(string): name of the tagvalue(string): optional value of the tag instance; if omitted, the values of the tag are the portions of text indicated inpositions
Each item of the positions array is a characters range.
In the case of information of type disambiguation, if the sub-type is token, each range corresponds to a different token, if instead it is semantic they are occurrences of the concept.
In the case of tag type information, each range corresponds to an occurrence of the tag, possibly with the same value, if specified.
Each item of the array is an object with two properties, start and end, which must be valued with the same logic as the positions of output elements.
document
Blocks corresponding to ML models placed in the workflow in advanced mode expect an input JSON with top-level key document. This key is an object with the same structure as the output of a symbolic model.
The reason for this is that the block doesn't have NL Core, in only contains the prediction model. It doesn't expect a text to analyze, it expects the features of the text extracted by a NLU analysis of the text that is can't perform. Features are the basis of model's predictions.
Any upstream block with NL Core can be used to perform feature extraction, for example you can use the NLP Core Knowledge Model, then the document input property must be mapped to the key with the same name in the output of the feature extraction block.