Splitters overview
A Splitter block marks the beginning of a portion of the workflow which is executed as many times as the items produced by the block itself by "splitting" its input. This portion of the workflow must be terminated with an End Context block.
In other words, after encountering a splitter, the workflow loops on the items produced by the splitter itself, executing, for each of them, the portion of the workflow between the splitter and End Context.
The blocks from the splitter itself to the corresponding End Context block are collectively called the context of the splitter. Visually, a context is recognizable by:
- A frame of the same color contouring all its blocks.
- The color of the internal connections, which is the same of the frame above.
- The double arrow icon halfway of the internal connections.

From the flow point of view, a context is, in itself, isolated from the rest of the workflow: it can produce n outputs, but these outputs are not transmitted downstream. So, for example, if a workflow only consists of a context, its output is an empty object.
To "pull out" the outputs from a context and make use of them, it is necessary to use a reducer or a remapper.
If you put a splitter in the context of another splitter you create a nested context.
For example, the outer context can loop on the PDF files extracted from a ZIP file with ZIP Splitter while the inner context can iterate on the pages of each PDF file with PDF Splitter to perform some per-page analysis.
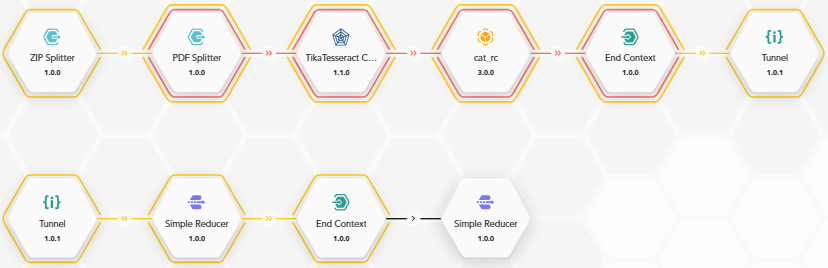
Graphically, the blocks belonging to a nested context have a number of concentric contours corresponding to the level of nesting: each contour corresponds to a context. In the example above the violet border is used for the internal context of PDF Splitter (nesting level: 1), while the green one corresponds to the external context of ZIP Splitter (outer context, no nesting).
The workflow in the example shown above works like this:
- The user has a ZIP file containing a certain number of PDF files, each having a certain number of pages.
- The user submits a JSON containing the Base64 representation of the ZIP file to the workflow. The JSON has the input format required by ZIP Splitter.
- The ZIP Splitter block decodes the Base64 representation, recreating the ZIP file from which it then extracts the PDF files.
-
Loop on PDF files (outer context):
- Each PDF file is submitted to PDF Splitter using a JSON.
- PDF Splitter "breaks" the file into pages, each page becoming a single-page PDF.
-
Loop on the pages of the PDF file (inner context):
- The single-page PDF file is submitted to the TikaTesseract Converter block which extracts the text.
- The text is submitted to the Page Analyzer symbolic model block which produces its results (e.g., categories).
-
After the PDF Splitter context, a Simple Reducer block creates a JSON containing the results for all the pages of a PDF file.
-
After the ZIP Splitter context, a Simple Reducer block creates a JSON that aggregates the n outputs of the multiple executions of the previous Simple Reducer in the desired way. This is the final output of the workflow: a JSON containing a section for each PDF file and, within it, the results of the analysis of each page.
Workflows containing splitters can only be published in asynchronous mode.
Warning
The splitter named Library document lister splitter is available only if the user belongs to the Owner role. It is meant to be used in system workflows which, in turn, are automatically generated and managed by the Platform. that splitter is a system component and must not be used in users' workflows.