Model types and properties
Model blocks are the main components of NL Flow workflows.
Their main task is to use a model—either ML or symbolic—to make predictions about the input text in terms of categories—the topics covered in the text or the typology of the document inferred from its text—or extracted information. Depending on the type, however, models can yield many other useful information.
Model types
These types of model can be used as blocks when designing a workflow:
| Type | Block icon | Description |
|---|---|---|
| Basic mode ML models |  |
Platform-generated ML models embedding NL Core for feature extraction |
| Advanced mode ML models |  |
Platform-generated ML models used without NL Core |
| Symbolic models |  |
Symbolic models, either generated with the Platform authoring application or generated/refined with Studio |
| Knowledge Models |  |
NL Flow built-in inventory models |
Basic mode ML models
ML models are generated in Platform authoring application. "Basic mode" refers to the way the corresponding blocks are put in the workflow, that is in basic/default mode.
The inner structure of a basic mode workflow block for a Platform-generated ML model is illustrated below.
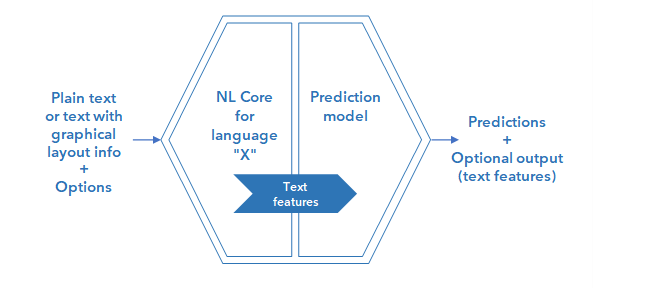
The input to the block is a JSON containing plain text, unless the model has been trained with annotations referring to the position of the text in the graphical rendering of the document: in that case the input JSON contains text enriched with graphical layout information (the output of Extract Converter processor).
Input can also include options.
NL Core performs NLU analysis of the text, extracting the text features with which the ML prediction model is then fed.
The main output of the block are the predictions (categories or extraction) plus, optionally, the output of NL Core.
Advanced mode ML models
Advanced mode ML models are ML models that are put in a workflow with the Advanced mode option. The effect of this option is to remove NL Core, leaving only the pure prediction model.
The inner structure of an advanced mode workflow block for a Platform-generated ML model is illustrated below.
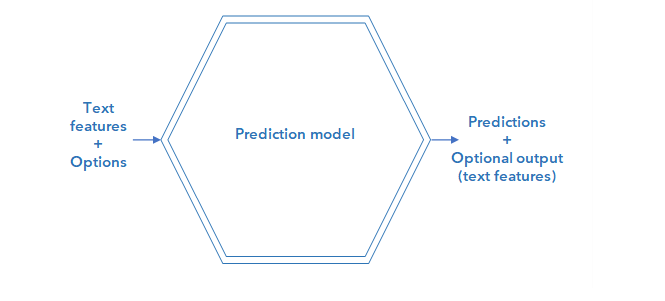
The input to the model block is a JSON containing text features. In fact, predictions are based on text features, but since the block doesn't contain NL Core, it cannot extract them by itself.
Input can also include options.
To provide the block with the necessary features, a symbolic model or a knowledge model like NLP Core is placed in the workflow upstream of the advanced mode ML model block and its output mapped to the input of the ML model.
The main output of the block are the predictions (categories or extractions) plus, optionally, the echo of the input text features.
Advanced mode is meant for workflows requiring more than one ML model: if every ML model is put in the workflow with the advanced mode option, one upstream symbolic model is enough to feed all the advanced mode ML model blocks with text features, as illustrated in the picture below.
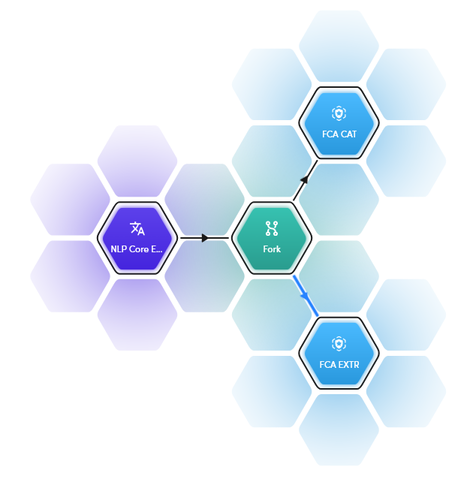
The result is a leaner and faster workflow: leaner because advanced mode ML models, lacking the NLU engine, require less computing resources to be published; faster because NLU analysis is performed only once per workflow activation instead of once per model.
Note
Advanced mode is available for ML models based on expert.ai ML technology version 3.0 or higher.
Symbolic models
Symbolic models use NL Core to get symbolic information about the input text and to evaluate categorization or extraction rules that use that symbolic information as their operands.
Note
Since the rules are human readable, it is always possible for a human to understand the reason for a result, hence these models are called explainable.
Platform-generated symbolic models
Platform authoring application allows for the automatic generation of symbolic models for categorization, extraction and thesaurus projects. Symbolic rules are produced as the result of model training.
The inner structure of the workflow block for a Platform-generated symbolic model is illustrated below.
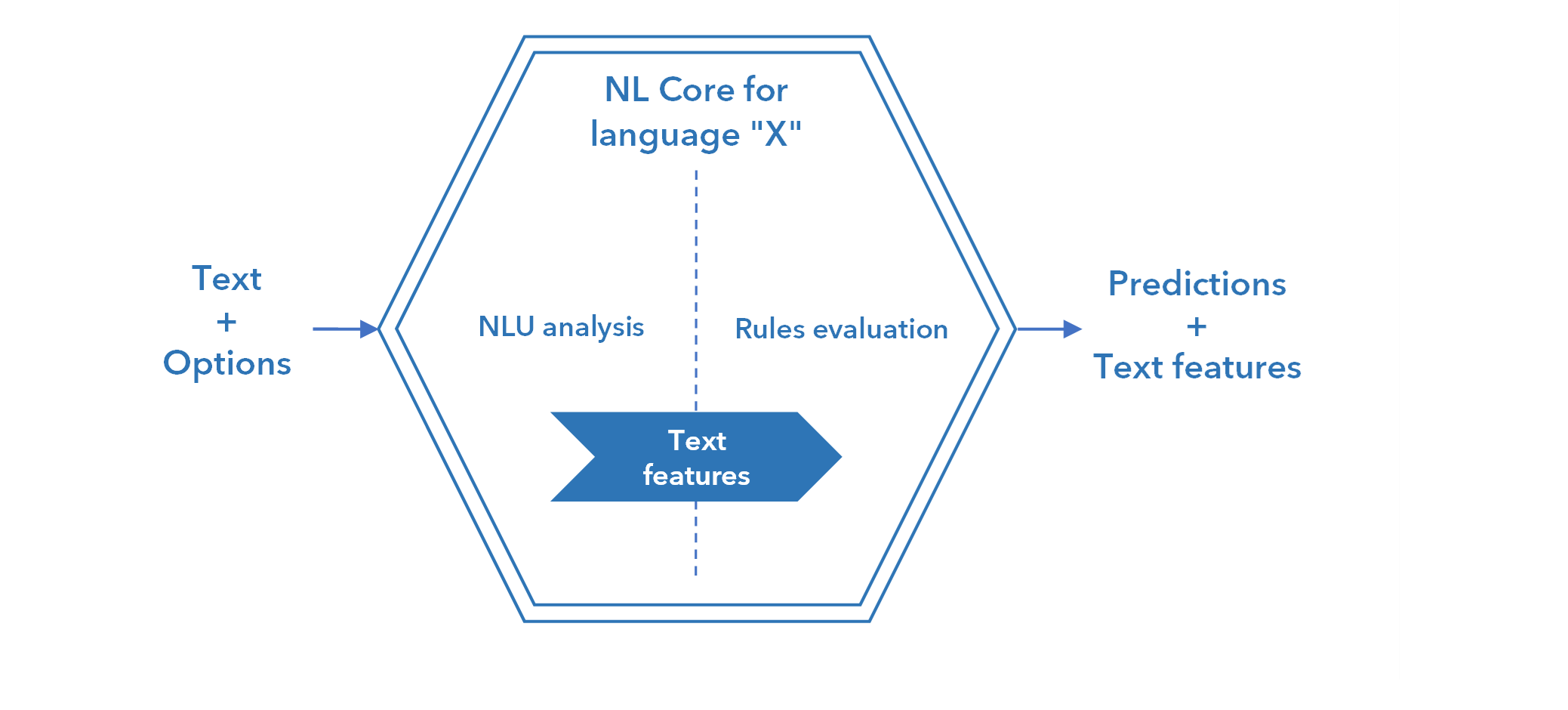
The model block is made of an instance of NL Core.
It expects a JSON containing plain text as its input, any other input is ignored. Input can also include options.
NL Core performs NLU analysis of the text, extracting text features that are then used by NL Core itself as the operands of automatically generated symbolic rules. The type of rules—categorization or extraction—depends on the Platform project type: categorization for categorization projects, extraction for extraction and thesaurus projects.
The main output of the block are the predictions (categories or extractions) plus the basic features of the text extracted by NL Core. Optionally it's possible to output more of those features.
Studio-generated symbolic models
If more human supervision is needed, symbolic models can be refined or even designed form scratch using Studio. Generated models can then be uploaded to Platform, to test them, and to NL Flow to use them in workflows.
When needed, Studio lets you generate models that combine categorization and extraction rules, something that is not doable with Platform alone. Studio also allows you to fully exploit all the capabilities of NL Core, like segmentation rules and JavaScript.
The inner structure of the workflow block for a Studio-generated symbolic model is illustrated below.
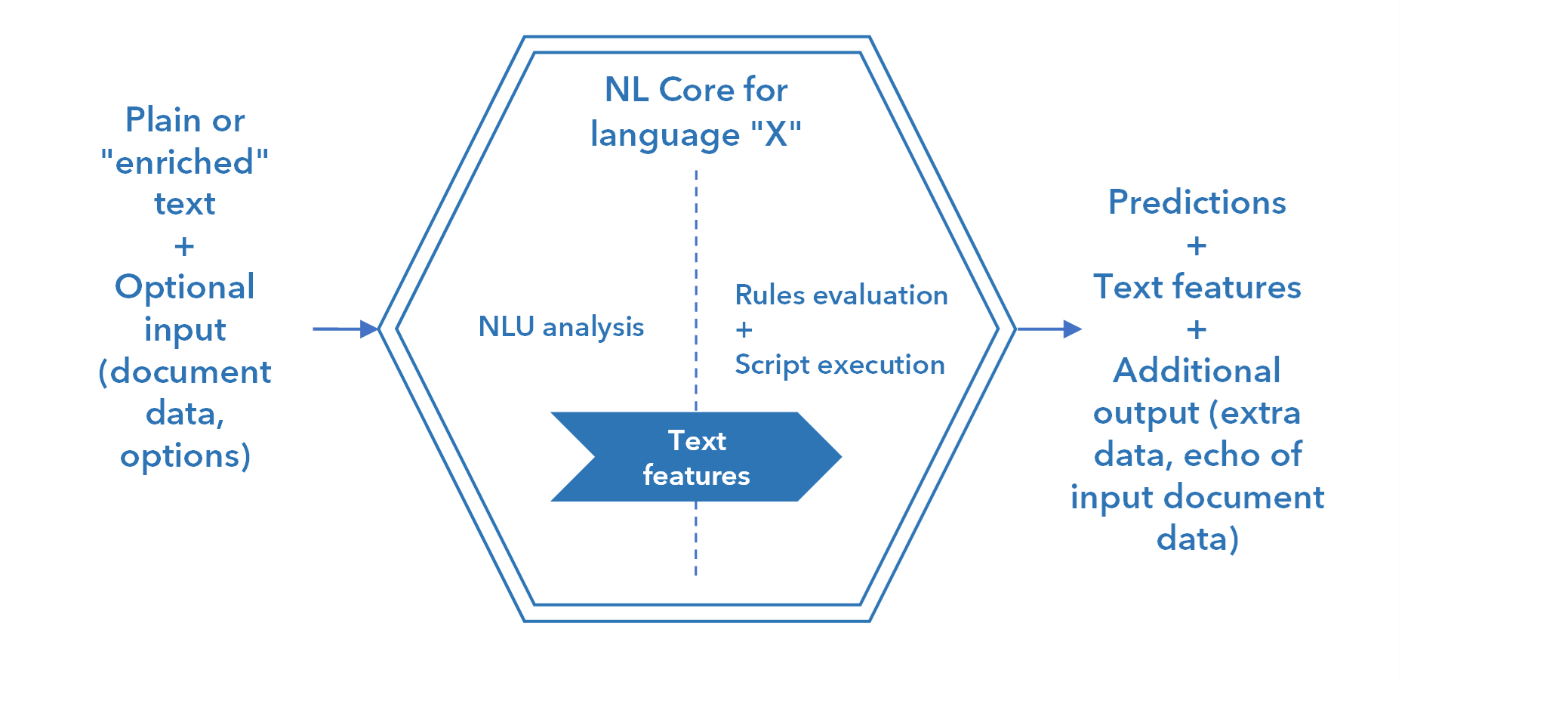
The block accepts a JSON with plain text or "enriched" text, that is text with graphical layout information (the output of the Extract Converter processor) or text divided in sections, plus optional additional input, like side-by-side document data and options. See the next page for a description of the input JSON.
NL Core performs NLU analysis of the text, producing text features that are used by NL Core itself as the operands of hand written categorization or extraction rules. Hand written rules can exploit all the expressiveness of the rules language, something that automatically generated rules do not.
NL Core also executes any JavaScript code with which the developers of the model can affect the document processing pipeline, for example pre-processing the input text and/or post-processing the results, possibly taking into account any custom options passed in input and producing extra output.
The main output of the block are the predictions (categories and/or extraction) plus the basic features of the text extracted by NL Core. Optionally it's possible to output more text features, layout information and any extra data generated by the JavaScript code.
Knowledge Models
Knowledge Models are built-in symbolic models that cover a variety of text analysis use cases.
Their inner structure is the same of Studio-generated symbolic models.
Learn more about them in the dedicated section of this manual.
Models availability
Every model created with the Platform authoring application is made available to NL Flow by publishing it.
In the authoring application models can also be exported to be later imported in the same or another installation of both the authoring application and NL Flow.
Studio models can the imported in NL Flow. The model import functionality is available in the Models view of the main dashboard and in the My Models bar of the editor.
Knowledge Models are always available.
Block properties
Block properties can be set by editing the block.
General properties
The general properties of any model block are displayed at the top of the properties pop-up. They are:
- The block name, displayed both in the title and in the text box below it, where it can be changed.
- The version of the software service that hosts the model (read only).
- The block ID (read only).
Functional properties
Functional properties can be checked and set in the Functional tab of the properties pop-up and they vary according to the model type.
Basic mode ML models
Basic mode ML models blocks have the following functional properties:
- ML Model: the prediction model of the block.
- ML Engine: propagate document content to output: make the model return the
contentoutput key. - ML Engine: output namespace: overrides the value of the
namespaceproperty of predictions (categories and extractions). - ML Engine: Output winner categories only: output only categories with the relatively highest scores, that is those with the
winnerproperty set totrue. -
Sub-document segmentation strategy: strategy used to identify the sub-documents on which to make category prediction. Auto-ML categorization models for which the Enable strict "Sub document categorization" compatibility mode option has been enabled can predict categories for each sub-document found in its input text, returning, for each category, the boundaries of the sub-document in the overall text. This parameter determines what a sub-document is. Possible values are:
- None: sub-documents, if any, are ignored, the predictions refer to the whole document text.
-
Extract Converter title: when the input to the model is the output of an Extract Converter block, a sub-document is:
- Any sequence of layout blocks that begins with a block of type title and ends either at the end of the document or immediately before another block of type title.
- Any table.
Consecutive title-type blocks are treated as a whole; header and footer blocks are ignored.
-
Extract Converter block: when the input to the model is the output of an Extract Converter block, the sub-documents are all the blocks of the layout except those of type header and footer.
- CPK segments: when the input to the model comes from a symbolic model originally generated with Studio and that model is able to detect and output text segments, sub-documents are the segments that are present in the output of that model.
-
Propagate symbolic engine output: when this option is turned on, NL Core output is included in the overall block output.
-
All these options:
- Apply rules
- Synchronize positions to original text
- Rules output namespace
- Output relevants
- Output sentiment
- Output relations
- Output dependency tree
- Output knowledge
- Output external ids
- Output rules extra data
- Output segments
- Required user properties for syncons
- Output explanations
- Output namespace metadata
- Output document data
- Output layout information
apply to NL Core and are the same of a symbolic model. They can affect the overall output of the model based on the Propagate symbolic engine output option (see above).
Advanced mode ML models
Advanced mode ML models blocks have the following functional properties:
- ML Model: the prediction model of the block.
- Propagate Content To Output: make the model return the
contentoutput key. - Propagate Symbolic To Output: when this option is turned on, the input to the block is included in the overall block output.
- Desired namespace: overrides the value of the
namespaceproperty of predictions (categories and extractions). - Only winners: output only categories with the relatively highest scores, that is those with the
winnerproperty set totrue. - Sub-document segmentation strategy: like the homonymous property of basic mode ML models.
Symbolic models
Symbolic models blocks have the following functional properties:
- CPK: the symbolic model of the block.
-
Synchronize positions to original text: model output can contain the positions—start, end—of elements in text, for example the position of parts of the text that triggered a category or the parts the correspond to extractions.
The input text to the model can be changed by the model itself before being analyzed: for example, sequences of new line characters can be reduced to one new line character or multiple consecutive space characters collapsed to one space character. The model, if made with Studio can also perform find-and-replace operations through JavaScript before analyzing the text.By default, positions refer to the analyzed text, which can thus differ from the original, and analyzed text is returned in output in the
contentkey, so if positions are used to highlight parts of the analyzed text, they are always accurate. This option must be turned on only if the user needs positions that refer to the original input text. When the option is turned on, the model rebases positions so that they are accurate for the original text, and the original input text is returned in output instead of analyzed text.Warning
Position rebasing can have some inaccuracies, especially if the model makes heavy changes to the input text before analyzing it.
-
Apply rules: when turned on, makes the model apply categorization and extraction rules, filling the
categoriesand theextractionsarrays based on the type of rules that are defined inside the model and are triggered. - Rules output namespace: overrides the value of the
namespaceproperty of predictions (categories and extractions). - Output relevants: when turned on, makes the model return the most important elements of the input text, that is the
topics,mainSentences,mainPhrases,mainSynconsandmainLemmasoutput keys. - Output sentiment: when turned on, makes the model return the
sentimentoutput key. - Output relations: when turned on, makes the model return the
relationsoutput key. - Output dependency tree: when turned on, makes the model return the
pos,dependencyandmorphologyproperties for each item of thetokensoutput array. - Output knowledge: when turned on, makes the model return the
knowledgeoutput key. - Output external ids: inside the Knowledge Graph used by NL Core, concepts—called syncons—are identified by a unique number. This number is the value of the
synconproperty of the items of thetokensand theknowledgeoutput keys.
Syncons have further identification numbers, so-called external identifiers (one or more) that are not shown by default in the model output.
When turned on, this property determines the addition to the output, for each item of theknowledgearray, of theexternaIdsarray listing those external identifiers.
Turning on this property is effective only if the Output knowledge property is turned on too (see above). - Output rules extra data: when turned on, makes the model return the
extraDataoutput key. Only models generated with Studio can optionally produce extra data. - Output segments: when turned on, makes the model return the
segmentsoutput key. Only Studio-generated symbolic models can optionally detect and output segments. - Required user properties for syncons: it allows you to specify the user data you want to be included in the output
knowledgesection. It's a comma separated list of user data names.
The following additional properties are available for models based on NL Core version 4.12 and later:
- Output explanations: enriches output with information about the symbolic rules that were triggered and brought to the prediction of categories and/or extractions.
- Output namespace metadata: make the model return the
namespacesoutput key. - Output document data: make the model return the
documentDataoutput key. -
Output layout information: make the model return the
layoutDataoutput key.Tip
You can determine the version of NL Core for a symbolic model by selecting Show resources
 in the editor or looking at the Resources area after selecting the model in the Models view of the main dashboard.
in the editor or looking at the Resources area after selecting the model in the Models view of the main dashboard.
If all output functional parameters are off, the model still performs basic analysis of the input text and named entity recognition with NL Core. This analysis produces output keys content, entities, language, options, paragraphs, phrases, sentences, tokens, and version. The categories and extractions arrays are also present in the output, but they are always empty unless Apply rules is turned on.
Knowledge Models
Knowledge Models have the same functional properties of symbolic models. The only difference is the Knowledge Model property with which you can change the model of the block.
Input properties
The input properties of a model block are the top level keys of the input JSON that the block can recognize. They are listed as individual fields with a drop down list each in the Input tab of the block properties pop-up.
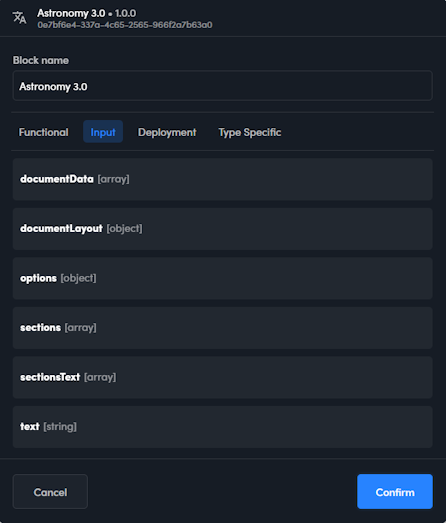
These properties need to be set only when input mapping is required.
In the next article you will find the detailed description of the keys of the input JSON that correspond to these properties.
Deployment properties
The deployment properties of a model block can be set in the Deployment tab of the block properties pop-up.

They express the resources required by the model when the workflow runs in Platform runtime. In order for a workflow to be published, the runtime must have a free amount of resources at least equal to the sum of those required by all the models in the workflow.
For symbolic models, advanced mode ML models and Knowledge Models, deployment parameters are:
- Replicas: number of required instances
- Memory: required memory per instance
- CPU: thousandths of CPU required (for example: 2000 = 2 CPUs) per instance
For basic mode ML models they are:
- Symbolic Engine Replicas: number of required instances for the symbolic engine
- Symbolic Engine Memory: required memory per instance of the symbolic engine
- Symbolic Engine CPU: thousandths of CPU required per instance of the symbolic engine
- ML Engine Replicas: number of required instances for the ML engine
- ML Engine Memory: required memory per instance of the ML engine
- ML Engine CPU: thousandths of CPU required per instance of the ML engine
Info
IEC units of measures are used for memory: Ki (kibibyte), Mi (mebibyte), Gi (gibibyte).
Type specific properties
The type specific properties of a model block can be set in the Type Specific tab of the properties pop-up.
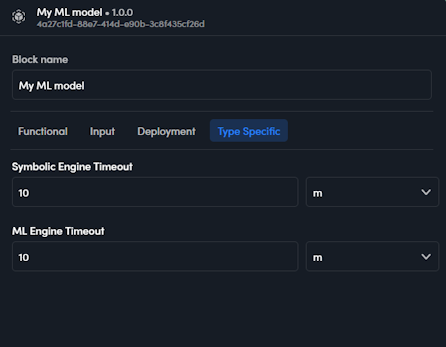
For symbolic models, knowledge models and advanced mode ML models, the only property is Timeout, which is the execution timeout.
For ML models there is a timeout property for each of the engines (symbolic and ML).
The drop down to the right of each property field allows specifying the unit of measure for the execution timeout, which can be minutes (m) or seconds (s).