Extract Converter processor
Description
The Extract Converter processor takes PDF documents as input and, page by page, extracts the text blocks together with their graphic layout. For each block, it determines the position on the page, the size and the type choosing between heading, body part, header, footer and table cell.
The processor also obtains further information such as the number of pages, author and creation date, the table of contents, the list of fonts used in the document and any PDF metadata.
When extracting text, Extract Converter can use Optical Character Recognition (OCR) to get plain text from images that represent text.
It is used as the first block of a workflow when it is certain that only PDF documents will be analyzed, as an alternative to the TikaTessaract Converter processor. With resepect to TikaTesseract Converter, Extract Converter, especially in case of documents with complex layouts—multiple columns, text boxes, figures—returns the text in an order more similar to that in which a human would read it, therefore more suited to being analyzed effectively with a model.
Input
The processor requires the input JSON to contain these top level keys:
"path": "filePath",
"base64": "base64Encoding"where:
filePathis the name of the file to process or its path.base64Encodingis the Base64 encoding of the file.
The value of path is only for logging or auditing purposes, it is not used to "read" the file, which instead is completely represented by the base64 value.
Block properties
Block properties can be set by editing the block.
Extract Converter workflow blocks have the following properties:
-
Common:
- The unique block ID and the service version, displayed in the title bar (read only, displayed also in the block tooltip in the canvas).
- Block name: the block name, it can be edited.
- Description: the description of the processor (read only).
-
Type Specific:
- Timeout: execution timeout expressed in minutes (m) or seconds (s).
-
Deployment:
- Replicas: number of required instances.
- Memory: required memory.
- CPU: thousandths of a CPU required (for example: 1000 = 1 CPUs).
-
Functional:
- Enable or disable table and title detection: toggles the recognition of tables and headings (enabled by default).
- Enable or disable OCR extraction: toggles Optical Character Recognition (OCR) to extract text from images (disabled by default).
-
Specify OCR language: when OCR is enabled, the language or script to be used to determine text. Possible choices are:
Value Description engEnglish chi_simChinese (simplified) chi_traChinese (traditional) hinHindi spaSpanish fraFrench araArabic benBengali rusRussian porPortuguese indIndonesian deuGerman itaItalian latnLatin script (any language with Latin characters) For multi-language documents, concatenate language codes with a plus character (+), for example:
eng+spa+ita. -
Enable/disable table of content extraction: toggles the extraction of the table of content, if any (enabled by default).
-
Enable/disable font extraction: toggles the extraction of the list of fonts used in the document (enabled by default).
-
Reading order mode: text extraction algorithm. Possible values are:
- standard: the algorithm tries to go from one text block to the next the way a human would do when reading the page. Best for multi-column or mixed layout pages.
- vertical: the algorithm considers the page as single-column and reads text blocks from left to right, from top to bottom.
- auto: the algorithm classifies each page based on its layout then automatically chooses between standard and vertical to extract text.
-
Input
These property correspond to the top level key of the input JSON.
They need to be set only when input mapping is necessary.
Output
Structure
The output of an Extract Converter block is a JSON object with the following structure:
{
"result": {
"fonts": [],
"header": {},
"layout": [],
"tableOfContents": [],
"words": []
}
}
where:
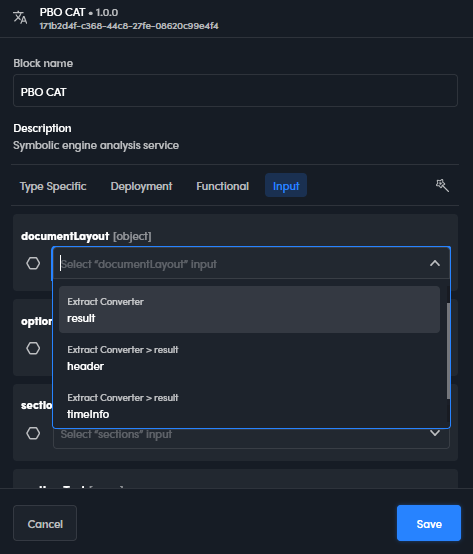
fontscontains a list of the fonts used in the document.headercontains general information about the document and the text extraction task.layoutcontains the document's layout, that is the text organized in a hierarchical structure with pages and corresponding text blocks.tableOfContentscontains the document table of contents (TOC), if any.wordscontains the document's text in words, without layout information.
fonts
This array lists the fonts used in the document's text. Each item in the array represents a font and has these properties:
| Key | Description |
|---|---|
bold |
true if bold, false otherwise |
id |
Unique font ID assigned during the analysis |
id_name |
Original font name |
italic |
true if italic, false otherwise |
name |
Normalized font name |
ocr |
true if recognized through OCR, false otherwise |
For example:
{
"bold": false,
"id": 1,
"id_name": "Arial",
"italic": false,
"name": "Arial",
"ocr": false
}
Note
If a font is not detected the key name is set to mix.
header
The header object contains information about the whole document and the extraction task. The properties are:
- conversionDateTime: extraction task end date and time.
-
customInfo: PDF document properties:
-
documentName: document name.
- errorPages: number of pages that could not be analyzed (present only in case of errors).
- options: extraction task options, for troubleshooting only.
- totPages: total number of pages.
- version: software version for the Extract Converter processor.
-
metadata: an array of PDF metadata.
Metadata is optional data that the PDF editor can insert into pages. This data is not displayed on the page, but is associated with visible elements.Each metadata can have these properties:
-
bbox: array containing the coordinates2 of the metadata bounding box.- item 0: upper left corner X
- item 1: upper left corner Y
- item 2: lower right corner X
- item 3: lower right corner Y
-
key: metadata key, its name. page: number of the page where the metadata is located.value: metadata value.
For example:
"metadata": [{ "bbox": [146, 207, 419, 228], "key": "txtPolicyNumber", "page": 3, "value": "PACUIC001101-07 " }, { "bbox": [39, 426, 417, 357], "key": "txtNamedInsuredAndAddress", "page": 3, "value": "SWEET FRUIT ASSOCIATION INC.\r\n7100 APRICOT WAY\r\nST. PETERSBURG, FL 33706 " }, { "bbox": [421, 356, 829, 438], "key": "AgencyNameAndAddress", "page": 3, "value": "StaySafe Insurance Services, Inc.\r\n2502 N Rodeo Drive\r\nTampa, FL 33607 " }, { "bbox": [144, 254, 283, 275], "key": "txtEffectiveDate", "page": 3, "value": "4/27/2022 " } ] -
layout
layout is an array containing all the layout elements recognized in the document.
The order of the elements inside the array reflects the sequence of pages, so all the elements of page 1 are found first, then those of page 2, and so on.
Within the elements of a page, the first element represents the page itself and the other elements are blocks of text, tables or table cells. The position of text blocks and tables in the array corresponds to what Extract Converter assumed to be the order in which a human would read them on the page.
Elements can represent:
- Pages (only the bounding box)
- Titles
- Headers
- Footers
- Body-level text blocks
- Tables (only the bounding box)
- Table cells
- TOC items
The properties that each element can have are:
Property ↓ |
Pages | Titles | Headers & footers | Body-level text blocks | Tables | Table cells | TOC items |
|---|---|---|---|---|---|---|---|
id |
X | X | X | X | X | X | X |
type |
X | X | X | X | X | X | X |
page |
X | X | X | X | X | X | X |
children |
X | X | |||||
parent |
X | X | X | X | X | X | |
content |
X | X | X | X | X | ||
bbox |
X | X | X | X | X | X | X |
label |
X | ||||||
row |
X | ||||||
column |
X | ||||||
isHead |
X | ||||||
span |
X | ||||||
relativePage |
X |
Properties are:
id: element ID, every element has a unique value for this property.-
type: element type. Possible values are:Element type typevalueDescription Pages pageThe "container" (it has no text of its own) of all the textual elements displayed on a page. Body-level text blocks textA block of text (e.g. a paragraph, a text box) at the body-level, i.e. not a title. Titles titleA heading. Tables tableThe "container" (it has no text of its own) of all the element (cells) of a table. Table cells cellA table's cell. Header headerA page header. Footers footerA page footer. TOC items tocAn item of the table of contents. -
page: page number children: list of child blocks' IDs, only in page and table elements. This property is an array, each item of which is the value of theidproperty of an element that is hierarchically a child of this element. For example, the titles in a page are children of the page element, the cells of a table are children of a table element.parent: parent element ID. In case of table cells, the value of this property is the value of theidproperty of the table element, while for title, text, header & footer and table elements, it is the value of theidproperty of a page element. Page elements don't have this property because their "parent" is the document itself.label: for titles, it specifies the title level as intableOfContents.content: text of the element, this property is absent in page and table elements, which are "containers".-
bbox: array containing the coordinates2 of the element's bounding box.- Item 0: upper left corner X
- Item 1: upper left corner Y
- Item 2: lower right corner X
- Item 3: lower right corner Y
-
row: cell row number. column: cell column number.isHead: set totrueif the cell is a column header.span: cell span. It's an array of integer numbers. When present, the cell spans over more than one row and/or columns. The first item of the array is the row span, the second is the column span.relativePage: the page label printed on the page. For example, page 4 could be labeled IV.
tableOfContents
This array represents the table of contents (TOC) of the document, if any, obtained both from explicit information of the PDF document and from the visual examination of the pages.
Each item in the array represents an entry in the TOC and has these properties:
| Name | Description |
|---|---|
score |
Item recognition confidence score |
level |
Title level on the titles' hierarchy. The value of this property coincides with the value of the label property of the corresponding title element in layout (see the layoutId property below) |
source |
Only for troubleshooting |
layoutId |
Cross-reference to the layout element. The value of this property coincides with the value of the id property of the corresponding title element in layout |
content |
TOC item text |
For example:
{
"score": 0.8755,
"level": 1,
"source": "d",
"layoutId": 2,
"content": "UMBRELLA LIABILITY POLICY SCHEDULE"
}
words
The words array contains one item per page and each item represents, in an encoded and compressed form, all the words present on the page.
The value of the single item is encoded in Base64.
The decoded value is a byte array in gzip format. The expanded byte array value is another byte array in which each word corresponds to a variable-length sequence of bytes with this structure:
UTF-8 encoded text0x00Parent element IDFont IDBounding box coordinatesUTF-8 encoded textis the text of the word.Parent element IDis four bytes long and must be interpreted as a little-endian integer. The value is the ID—the value of theidproperty—of the layout element in which the word is located.Font IDis four bytes long and must be interpreted as a little-endian integer. The value is the ID of the font with which the word is written in the document, so it coincides with the value of theidproperty of the item of the fonts array that represents the font.-
Bounding box coordinatesis 16 bytes long and consists of four parts of four bytes each. Each part must be interpreted as a little-endian integer. The parts are the coordinates2 of the word bounding box and, taken from left to right, have this meaning.- upper left corner X
- upper left corner Y
- lower right corner X
- lower right corner Y
Output-input mapping
The result top level key in the output JSON is compatible with the documentLayout input property of model blocks.
-
PDF defines a standard date format similar to the international standard Abstract Syntax Notation One (ASN.1), defined in ISO/IEC 8824. A date-time is a string with this format:
D:YYYYMMDDHHmmSSOHH'mm'where
YYYYis the yearMMis the monthDDis the day (01-31)HHis the hour (00-23)mmis the minute (00-59)SSis the second (00-59)Ois the relationship of local time to Universal Time (UT), denoted by one of the characters+,-, orZ(see below)HHfollowed by'is the absolute value of the offset from UT in hours (00-23)mmfollowed by'is the absolute value of the offset from UT in minutes (00-59)
A plus sign (
+) as the value of theOfield signifies that local time is later than UT, a minus sign (-) that local time is earlier than UT, and the letterZthat local time is equal to UT. If no UT information is specified, the relationship of the specified time to UT is considered to be unknown. Whether or not the time zone is known, the rest of the date is specified in local time.
For example, December 23, 2022, at 7:52 PM, U.S. Pacific Standard Time, is represented by the string:D:20221223195200-08'00'OR
D:20220327195230+05'00' -
Coordinates are in pixels and referred to a 100 DPI (dots per inch) rendering of the page. The coordinates origin is at the top left corner of the rendered page. ↩↩↩