Knowledge graph extension and patch file formats
Introduction
This article describes the characteristics of the source files that can be used to extend and patch the knowledge graph.
You need to use plain text files, which can be .txt files or comma-sperated values (CSV) files with .csv extension.
The former are used only to add syncons corresponding to named entities, while the latter allow for more operations described below for extending and patching the knowledge graph.
Warning
You can't use .txt files for patch operations.
In case of extension and patch operations, two files are necessary:
- One for the extension to be loaded in the Extension tab of the Knowledge Graph Editor Settings window.
- One for the patch to be loaded in the Patch tab of the Knowledge Graph Editor Settings window.
Below, you will find the description of the formats with CSV example files for patches and extensions and an Excel template.
.txt files
Use .txt files if all you need to do is add named entities to the knowledge graph.
Files with the .txt extension must contain a line for each entity you want to add. For each entity a knowledge graph syncon will be created.
The syncon lemmas, that is the main lemma plus any synonyms, must be entered in each line.
For example, a file with these contents:
Ferdinand Lewis Alcindor Jr.,Kareem Abdul-Jabbar
Larry Bird
Dr. J,Julius Erving
Karl Malone,The Mailman
Earvin Johnson,Magic Johnson
corresponds to five syncons, each of which represents a distinct entity.
To separate the lemmas, you can use comma (,), pipe (|) or semicolon (;).
If a file contains lemmas with a comma, like ACME, Incorporated or Los Angeles, CA, use another of the possible characters to separate lemmas.
.csv files
File extension
CSV files must have the .csv extension.
Headings
The first row is dedicated to field headings, all the other rows specify the operations to be performed to extend and/or patch the knowledge graph. Each row can be considered a "record" with "fields" corresponding to the headings based on their position. The possible fields are described below.
Column headers must not be removed if the columns are empty. It is possible to swap columns.
Warning
Don't use .csv files used in legacy projects, because they have a different structure compared to those currently available. See downloadable samples below.
Excel options and separator character
It is common to produce CSV files by exporting single sheets from an Excel document.
The knowledge graph extension and patch procedures allow importing CSV files where the field separator is one of the following characters:
,(comma), this is the default value when exporting Excel sheets to CSV from a computer with a US or UK English locale. Values containing commas, like Apple, Inc., are enclosed in double quotes ("Apple, Inc.").;(semicolon), this is the default value when exporting Excel sheets to CSV from a computer with a locale in which the comma is the decimal separator (e.g., Italian, French, German).|(pipe)\t(tab), this is the default separator when saving tab-separated values (TSV). If the Excel export procedure generates a file with the.txtextension, it must be changed to.csv.
In general, an Excel sheet can be exported to a valid CSV file by selecting one of these formats in the Save As... dialog:
- CSV UTF-8 (Comma delimited) (*.csv): in this case the file will be encoded as UTF-8 with BOM with columns separated by the character defined by the specific locale.
- CSV (Comma delimited) (*.csv): this is the same as above, but the file will be encoded as ANSI and therefore will not contain special characters (e.g., Russian, Chinese, Japanese, etc.), so it should be used just when the input only contains Latin characters (e.g. Windows-1252).
- Text (Tab delimited) (*.txt): this saves the file as TSV (tab-separated), with the
.txtextension, so it should be renamed changing it to.csv. The file will be ANSI encoded as for the choice above.
The order in which the field headings are listed in the first row of the file is not important. Fields corresponding to unexpected headings are ignored by the import procedure.
operation
It is the only field that is always required. Allowed values for extension operations are:
ADDSYN: causes the creation of a new syncon.ADDLINK: causes the creation of a link of typelinkbetween synconparentand synconid.ADDUSERDATA: causes the addition of user data with keyuserkeyand valueuservalueto synconid.
Other fields may be optional, ignored or required on the basis of the operation type according to the following scheme.
operation | id | type | gloss | lemma | weight | freq | parent | link | domain1 | domain2 | userkey | uservalue |
ADDSYN | Optional | Optional | Optional | Required | Optional | Optional | Required | Optional | Optional | Optional | Optional | Optional |
ADDLINK | Required | Ignored | Ignored | Ignored | Ignored | Ignored | Required | Required | Ignored | Ignored | Ignored | Ignored |
ADDUSERDATA | Required | Ignored | Ignored | Ignored | Ignored | Ignored | Ignored | Ignored | Ignored | Ignored | Required | Required |
Allowed values for patch operations are:
DELSYN: delete a specified synconid.ADDLEMMA: add a lemma to a specified synconidwith optional weight and frequency.CHANGELEMMA: change weight and frequency of a lemma of a selected synconid.DELLEMMA: delete a lemma of a selected synconid.DELLINK: delete a link of typelinkbetween synconparentand synconid.DELUSERDATA: delete user data with keyuserkeyand valueuservalueto synconid.CHANGESYN: change syncon properties like its type, gloss or domains.ADDLINK: cause the creation of a link of typelinkbetween synconparentand synconid.ADDUSERDATA: cause the addition of user data with keyuserkeyand valueuservalueto synconid.
Other fields may be optional, ignored or required on the basis of the operation type according to the following scheme.
operation | id | type | gloss | lemma | weight | freq | parent | link | domain1 | domain2 | userkey | uservalue |
DELSYN | Required | Ignored | Ignored | Ignored | Ignored | Ignored | Ignored | Ignored | Ignored | Ignored | Ignored | Ignored |
ADDLEMMA | Required | Ignored | Ignored | Required | Optional | Optional | Ignored | Ignored | Ignored | Ignored | Ignored | Ignored |
CHANGELEMMA | Required | Ignored | Ignored | Required | Required | Required | Ignored | Ignored | Ignored | Ignored | Ignored | Ignored |
DELLEMMA | Required | Ignored | Ignored | Required | Ignored | Ignored | Ignored | Ignored | Ignored | Ignored | Ignored | Ignored |
DELLINK | Required | Ignored | Ignored | Ignored | Ignored | Ignored | Required | Required | Ignored | Ignored | Ignored | Ignored |
DELUSERDATA | Required | Ignored | Ignored | Ignored | Ignored | Ignored | Ignored | Ignored | Ignored | Ignored | Required | Ignored |
CHANGESYN | Required | Optional | Optional | Ignored | Ignored | Ignored | Ignored | Ignored | Optional | Optional | Ignored | Ignored |
ADDLINK | Required | Ignored | Ignored | Ignored | Ignored | Ignored | Required | Required | Ignored | Ignored | Ignored | Ignored |
ADDUSERDATA | Required | Ignored | Ignored | Ignored | Ignored | Ignored | Ignored | Ignored | Ignored | Ignored | Required | Required |
Note
In case of CHANGESYN at least one of the optional values must be specified for the operation to make sense.
id
This is the numeric ID of the syncon involved in the operation. It is optional for the ADDSYN operation and required for the other patch and extension operations. When optional, ID (default starting value is 6000000) will be automatically set to the first available ID value.
If specified for ADDSYN operations—which generate new syncons—it must be a positive integer number—with no thousand separator—between 6000000 and 9000000.
type
The word class of the syncon being added.
It is optional for the ADDSYN and CHANGESYN operations, the default value being NPR. It is ignored for other operations.
gloss
The gloss, that is a human-readable definition of the syncon. It is optional for the ADDSYN and CHANGESYN operations, the default value being "no gloss". This field is ignored for other operations.
lemma
One or more lemmas for the syncon. This field is required for:
ADDSYNADDLEMMADELLEMMACHANGELEMMA
It is ignored for the other operations.
Multiple lemmas must be separated with a comma (,).
Each lemma must be shorter than 255 characters.
If any lemma contains non-ANSI characters, the CSV file must be UTF-8 encoded.
If a lemma contains commas, they must be escaped by prefixing them with a backslash character (\), for example: Los Angeles\, CA. If a backslash is part of the lemma's value, it must be escaped by doubling it, For example, AC\\DC1.
weight
The weight for the lemmas of the syncon.
It is optional for the ADDSYN and ADDLEMMA operations, required for CHANGELEMMA, ignored for other operations.
The weight is an integer between 1 and 8. If multiple weights are specified, they must be separated with commas. The specified weights correspond to the lemmas based on their position in the sequence of comma separated values.
The default value in case of ADDSYN and ADDLEMMA operations is 1 for the first lemma of the list—which will become, in case of ADDSYN operations, the main lemma for the syncon—and 2 for any other lemma for which the weight is not specified.
If more weights than lemmas are provided, excess values are ignored.
freq
The frequency for the lemmas of this syncon.
It is optional for the ADDSYN and ADDLEMMA operations, required for CHANGELEMMA, ignored for other operations.
The frequency is an integer between 1 and 99. If multiple frequencies are specified, they must be separated with commas. The specified frequencies correspond to the lemmas based on their position in the sequence of comma separated values.
The default value in the case of ADDSYN and ADDLEMMA operations is 1 for any lemma for which the frequency is not specified.
If more frequencies than lemmas are provided, excess values are ignored.
parent
The parent syncon ID. It is required for:
ADDSYNADDLINKDELLINK
and ignored for the other operations.
It can be the ID of a syncon added during the knowledge graph extension operation, whose ADDSYN operation therefore comes before in the file or in another imported file, or the ID of a syncon which is already present in the base knowledge graph.
The value of this field is used to link the syncon specified by id with the syncon specified by parent via the link specified by link.
link
The name of the link used to connect the syncon specified by id with that specified by parent.
This field is optional for the ADDSYN operation, required for ADDLINK and DELLINK, ignored for other operations.
The default value is superverbum/subverbum if type is VER, supernomen/subnomen otherwise.
For ADDSYN and ADDLINK operations, the value of link can be:
- The name of one of the links already available in the Knowledge Graph tool window.
- A custom value for
ADDLINKoperations.
Available links in the Knowledge Graph tool window are:
supernomen/subnomensuperverbum/subverbumomninomen/parsnomensyncon/geographygeography/structures
Tip
When adding new syncons, it makes sense to use the knowledge graph as much as possible by selecting a relation such as supernomen/subnomen or superverbum/subverbum.
In case of custom values, the extension procedure will display a warning message to make sure the user actually meant to create a new link and did not just misspell the name of an existing one, as in supernomen/subnomem.
In case of DELLINK the value of the field is the name of an existing link.
Custom link names cannot contain spaces or underscore characters (_).
domain1
A knowledge graph domain, with an optional frequency, to be added to the syncon as an attribute. The field is optional for ADDSYN and CHANGESYN operations, it's ignored for other operations. The default value is empty, which means "no domain".
The value has this syntax:
domain[,frequency]where domain is one of the knowledge graph domains and frequency is an integer number between 1 and 100. The default value for frequency is 50.
Note
Do not write the square brackets. In the syntax above they denote that ,frequency is optional, so if you don't want to specify the frequency write domain only, otherwise write domain,frequency.
The sum of frequencies for domain1 and domain2 must be lower than or equal to 100.
domain2
Second knowledge graph domain for the syncon. It is like domain1, but since a syncon can have up to two domains, this field allows for setting both.
userkey
The name of a user data that will be added to the syncon. The field is required for ADDUSERDATA and DELUSERDATA operations, it is optional for ADDSYN operations and it's ignored for the other operations.
If not specified for an ADDSYN operation, it defaults to empty, that is "no user data", but it is required if uservalue has been specified.
uservalue
The value of the user data specified by userkey. The field is required for the ADDUSERDATA and DELUSERDATA operations, it is optional for the ADDSYN operation and it's ignored for the other operations.
If not specified for an ADDSYN operation, it defaults to empty, that is "no user data", but it is required if userkey has been specified.
Examples
These files are examples:
The first file uses the comma as a field separator and the quotation marks—text delimiters—to quote values that contain the comma, such as that of the lemma column, which can contain multiple lemmas.
The file contains three rows in addition to the header row, all referring to the same syncon. In the first row the operation is ADDSYN and causes the addition of the syncon. In the second row, the operation is ADDLINK and causes the creation of a link between the newly added syncon and another syncon of the knowledge graph, in addition to the supernomen/subnomen link already created due to the first row. In the third row, the operation is ADDUSERDATA and it determines the addition of a key-value pair of data to the syncon.
The second file contains more than 2800 lines, all with operation ADDSYN, so each line adds a new concept to the graph. Each new concept is linked via the supernomen/subnomen link to an already existing concept. Also note the setting of domain1 and domain2.
The third file contains some examples with:
ADDLEMMADELLEMMACHANGELEMMACHANGESYNDELSYN
As you can see, several actions are performed: some lemmas are added, others are deleted, some syncons are deleted, others are modified.
Excel template
A useful Excel template to produce CSV files for extension and patch operations is downloadable. Two different tabs are available:
- Patch for patch operations
- Extension for extension operations
This template helps you fill the rows with the data (optional and mandatory) needed to perform the knowledge graph operations since different columns should be compiled according to the operation you need to perform.
Selecting the first blank cell of the sheet, a drop-down list button will appear. By clicking on it, a list of available knowledge graph operations will be displayed.
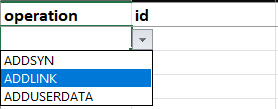
Selecting one, the cells you may need to fill in will be colored with the following meaning:
- Light blue: mandatory cell that needs to be filled in with proper data.
-
Light green: optional cell that you may or may not fill with proper data.
Note
The knowledge graph import process won’t warn you about anything if you leave it empty.
-
No color: uncolored cells must be left blank.
To produce a CSV file:
- Download and open the Excel template.
- Keep the desired sheet template—Patch or Extension—and delete the other one.
- Select the desired knowledge graph operation and fill in the cells based on their color.
-
Once you have compiled the sheet with all data, right-click the select all button and select Copy.
-
Select File > New > Blank workbook to create a new sheet.
- Right-click the A1 cell and select Values (V) from the Paste Options.
- Select File > Save As > Browse > Save as type and select CSV UTF-8 (Comma delimited)(*.csv), then save the file.
- Open the
.csvfile using a text editor to be sure no extra comma-separated characters were added in empty rows. - Import your file in Studio.
-
Indeed it's AC/DC, but we needed an example :-) ↩