Model types and properties
Model types
These types of model can be used as blocks when designing a workflow:
| Type | Block icon | Description |
|---|---|---|
| ML models |  |
Models based on hybrid technology, combining a symbolic and an ML engine |
| Symbolic models |  |
Purely symbolic models |
| Knowledge Models |  |
Built-in inventory models |
| Custom components |  |
Installation or customer specific components |
ML and symbolic models are created with the authoring application and made available to the Workflow application through publication or exported from the authoring application and then imported into the Workflow application. Available models are listed in the Components panel of the workflow editor or in the Models view of the main dashboard.
Block properties
Block properties can be set by editing the block.
General properties
The general properties of any model block are:
- The unique block ID and the service version, displayed in the title bar (read only, displayed also in the block tooltip in the canvas).
- Block name.
- Description.
Only the block name can be changed.
Type specific properties
The type specific properties of a model block can be set in the Type Specific tab of the block properties window.
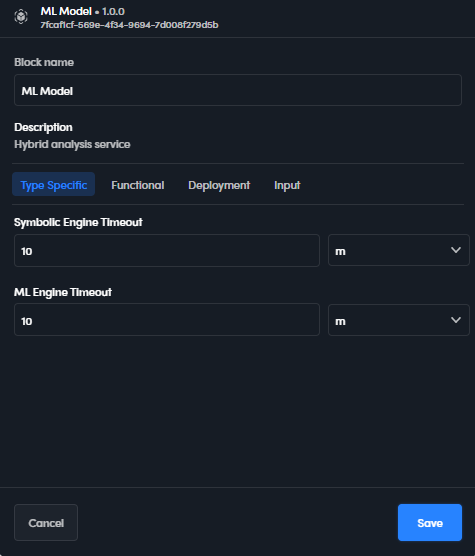
For Symbolic or Knowledge Models, the only property is Timeout, which is the execution timeout.
For ML models, the properties are:
- Symbolic Engine Timeout
- ML Engine Timeout
These are the execution timeouts of the two model components, symbolic and ML.
The timeout can be expressed in minutes (m) or seconds (s).
Functional properties
Functional properties can be set in the Functional tab of the block properties window and they vary according to the model type.
Note
In the following description, admitted values are indicated in round brackets next to each parameter name, with the possible default value in squares.
ML models
ML models blocks have the following functional properties:
- ML Engine: propagate document content to output ([on]/off): make the model return the
contentoutput key. - ML Engine: output namespace (string): output keys for the ML step of the model may have a
namespaceproperty. This option allows overriding the default value of that property. - ML Engine: Output winner categories only (on/[off]): output only categories with property
winnerset totrue. - Propagate symbolic engine output (on/[off]): when this option is turned on, the output of the symbolic step is included in the overall block output.
-
All these options:
- Apply rules
- Synchronize positions to original text
- Rules output namespace
- Output relevants
- Output sentiment
- Output relations
- Output dependency tree
- Output knowledge
- Output external ids
- Output rules extra data
- Output segments
affect to the symbolic step of the model and are the same of a purely symbolic model. They have an effect on the overall output of the model based on the Propagate symbolic engine output option (see above).
Symbolic models
Symbolic models blocks have the following functional properties:
- Synchronize positions to original text (on/[off]): model output can contain the positions—start, end—of elements in text, for example the position of parts of the text that triggered a category or the parts the correspond to extractions.
The input text to the model can be slightly changed—optimized—by the model itself before being analyzed: for example, sequences of new line characters can be reduced to one new line character or multiple consecutive space characters collapsed to one space character. By default, positions refer to the analyzed text, which can thus slightly differ from the original. Analyzed text is returned in output, so if positions are used to highlight parts of it, they are always accurate. This option must be turned on only if the user needs positions that refer to the original input text. When the option is turned on, the model rebases positions so that they are accurate for the original text, which means they could not be accurate for the analyzed text. - Apply rules ([on]/off): directs the model to apply categorization and extraction rules, which is the default behavior.
- Rules output namespace (string): some of the ouptput keys for a symbolic model have a
namespaceproperty. This option allows overriding the default value of that property. - Output relevants ([on]/off): make the model return the most important elements of the input text, that is the
topics,mainSentences,mainPhrases,mainSynconsandmainLemmasoutput keys. - Output sentiment (on/[off]): make the model return the
sentimentoutput key. - Output relations (on/[off]): make the model return the
relationsoutput key. - Output dependency tree (on/[off]): make the model return the
pos,dependencyandmorphologyproperties for each item of thetokensoutput array. - Output knowledge (on/[off]): make the model return the
knowledgeoutput key. - Output external ids (on/[off]): inside the Knowledge Graph used by the model for the semantic analysis of the input text, concepts—called syncons—are identified by a unique number. This number is the value of the
synconproperty of the items of thetokensoutput key.
Syncons have further identification numbers, so-called external (one or more) that are not shown by default in the model output.
This option determines the addition to the output, for each element of theknowledgekey, of theexternaIdslisting those external identifiers.
Activating the option is effective only if the Output knowledge option is also activated (see above). - Output rules extra data (on/[off]): make the model return the
extraDataoutput key. Note that not all symbolic models generate extra data, so the key can still be missing from the output even if this option is turned on. - Output segments (on/[off]): make the model return the
segmentsoutput key. - Required user properties for syncons (comma separated list): it allows you to specify which custom user data you want in the output
knowledgesection.
Knowledge Models
Knowledge Models have the same functional properties of purely symbolic models.
Deployment properties
The deployment properties of a model block can be set in the Deployment tab of the block properties window.
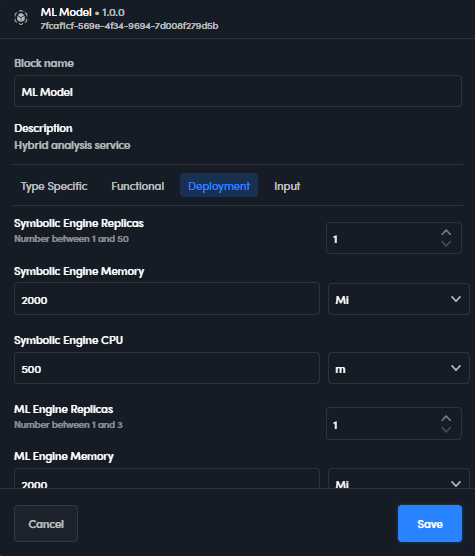
They express the resources required by the model when the workflow runs in Platform runtime. In order for a workflow to be published, the runtime must have a free amount of resources at least equal to the sum of those required by all the models in the workflow.
For symbolic models and Knowledge Models the deployment parameters are:
- Replicas: number of required instances
- Memory: required memory
- CPU: thousandths of a CPU required (for example: 2000 = 2 CPUs)
For ML models they are:
- Symbolic Engine Replicas
- Symbolic Engine Memory
- Symbolic Engine CPU
- ML Engine Replicas
- ML Engine Memory
- ML Engine CPU
IEC units of measures are used for memory: Ki (kibibyte), Mi (mebibyte), Gi (gibibyte).
Input properties
The input properties of a model block can be set in the Input tab of the block properties window.
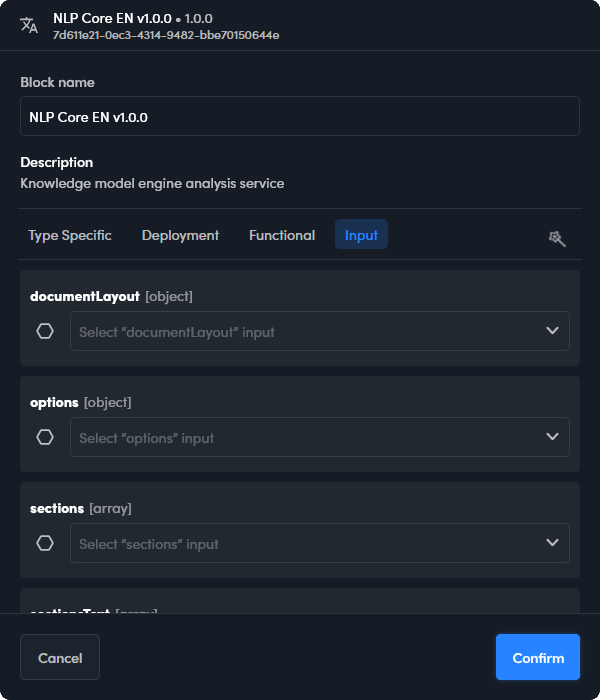
These properties act like a filter to determine the block input with respect to the output of upstream blocks or to the overall input to the workflow, if the definition of such input has been formalized.
The properties correspond to the top level keys—sometimes mutually exclusive, like documentLayout and text—of the JSON that the model is capable of interpreting. The type of each key is indicated in square brackets next to its name.
Setting these properties is called mapping and it is necessary when it is not possible for NL Flow to automatically determine which top level keys of the JSON produced by the previous blocks or submitted to the workflow via API should be considered by the model block as its input.
The need for mapping is automatically highlighted in the editor, which shows the model block surrounded by a dashed line and displays a warning message.
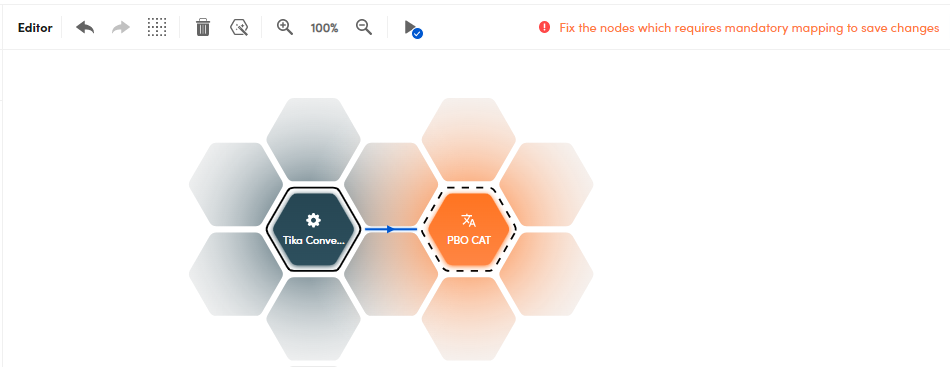
On the next page you will find the detailed description of the keys of the input JSON that correspond to these properties.