Model output keys
Introduction
The previous page describes the overall structure of the output JSON object of any model block in a workflow.
Here is the description of all the keys that can be present in the output: actual keys depend on the setting of the functional parameters of the block, possibly other parameters set when the model is generated and overriding values in the input JSON.
categories
The categories array, a property of the document object, is present in the output of models performing document classification.
It is the list of categories predicted by the model block.
Each item of the array is an object representing a category, like this:
{
"frequency": 70.62,
"hierarchy": [
"Sport",
"Competition discipline",
"Basketball"
],
"id": "20000851",
"label": "Basketball",
"namespace": "iptc_en_1.0",
"positions": [
{
"end": 14,
"start": 0
},
{
"end": 53,
"start": 35
},
{
"end": 139,
"start": 136
}
],
"score": 4005.0,
"winner": true
}
Based on the functional properties of the block and the version of the underlying software modules, it can have all of some of these properties:
id(string): category ID.label(string): category label, if any.hierarchy(array): in the case of a branched taxonomy, labels of all categories along the path from the root of the tree to the predicted category (included).score(number): prediction score. For ML models it can also be negative. For symbolic models it ranges from 0 to infinite and is the cumulative score that was attributed to the category by the categorization rules.frequency(number): relative score. For ML models is conventionally set to 100, while for symbolic models it is the percentage ratio of the category score to the sum of all categories scores. If the sum of thefrequencyvalue for all categories is less than 100 it means that the model is programmed not to return the categories with the lowest scores.winner(boolean):trueif the score is relatively high,falseotherwise. The values of this key are affected by the ML Engine: Output winner categories only and the Only winners functional properties of the model block.-
positions(array): positions of the text blocks that determined the prediction. For ML models they can include the characters' ranges of sub-documents when:- The Enable strict "Sub document categorization" compatibility mode option was enabled in the authoring application when generating the ML model.
- The ML model has been placed in the workflow in advanced mode.
- In the workflow the block of the ML model is preceded by the block of a symbolic model capable of identifying and returning segments.
- The symbolic model block has functional property Output segments enabled.
- The document input property of the ML model block is mapped to the document key of the symbolic model block output.
- The Sub-document segmentation strategy functional property of the ML model block has been set.
The items of the
positionsarray can also have ageometryproperty like this:{ "end": 23419, "geometry": [ { "box": [ 556, 443, 597, 457 ], "page": 7, "pageHeight": 1170, "pageWidth": 827 } ], "score": 90, "start": 23402 }This may happen when the input to the model is the output of an Extract Converter processor block or has the same structure.
-
explanations(array): information explaining the prediction in detail. It is always present for ML models, while for symbolic models it's present only if the Output explanations functional parameter is turned on.
For ML models, each item in the array is an object with these properties:-
mlDetails(object): name and value of the feature that determined the prediction. The object has these properties:featureName(string): name of the feature.featureValue(string): value of the feature.
-
positions(array): positions of the text blocks corresponding to the feature. Each array item is an object with these properties: -
score(number): contribution of the feature to the overall prediction score. type(string): constant ml.
For symbolic models, each item in the array is an object with these properties:
-
positions(array): positions of the scope of the categorization rule. Each array item is an object with these properties:end(number): end position of the scope.-
positions(array): positions of the hits of rule's operand inside the text. Each array item is an object with these properties: -
score(number): contribution of the scope to the overall prediction score. start(number): start position of the scope.type(string): constant scope.
-
ruleDetails(array): information about the rules that determined the prediction. Each item of the array is an object with these properties:id(number): zero-based sequence number of the rule.label(string): rule's label, if any.
-
score(number): contribution of the rule to the overall prediction score. type(string): constant rule
-
-
namespace(string): name of the software module carrying out the categorization.
content
The content key is a property of the document object and it's the text that has been analyzed.
document
The document key is an object that contains the results of a document analysis. It is common to all model blocks.
{
"document": {
analysis results
}
}documentData
The documentData array is a property of the document object.
It is an exact copy of the input key with the same name.
entities
The entities array is a property of the document object.
It is the result of the named entity recognition activity performed by the symbolic engine.
Each item in the array represents a named entity like this:
{
"lemma": "National Basketball Association",
"positions": [
{
"end": 139,
"start": 136
}
],
"syncon": 206693,
"type": "ORG",
}
where:
-
The
synconand thelemmaproperties are respectively the outcome of the semantic analysis and lemmatization:syncon(integer): ID of the Knowledge Graph entry corresponding to the entity.
The value -1 means the entity was heuristically recognized since there's no Knowledge Graph entry for it.lemma(string): lemma—or base form—of the entity name.
-
positions(array): it contains the positions of the entity occurrences in the text. type(string): entity type abbreviation.
extractions
The extractions array, a property of the document object, is present in the output of models performing information extraction, including thesaurus models.
It is the list of extraction predicted by the model block.
Each item of the array is an object representing an extraction, like this:
{
"fields": [
{
"name": "ingredients",
"positions": [
{
"end": 502,
"score": 0.9969,
"start": 494
}
],
"score": 0.9969,
"value": "potato"
}
],
"namespace": "hybridml",
"template": "ingredients"
}
Based on the functional parameters of the block and the version of the underlying software modules, it can have all of some of these properties:
template(string): template name. In Platform extraction projects terminology the corresponding term is group, that is the group the class belongs to. It's always thesaurus for thesaurus models.-
fields(array): each item corresponds to the extraction of a class and it is an object with these properties:name(string): field name, that is the information class in Platform extraction projects terminology. It's always concept for thesaurus models.value(string): extracted value.score(number): confidence score attributed to the extraction. It is a number between 0 and 1.-
positions(array): positions of the text blocks that determined the extraction. Each item of the array is an object with these properties:start(number): start position of the text block.end(number): end position of the text block.score(number): share of the prediction score due to the text block.-
explanations(array): information explaining the prediction in detail. It is always present for ML models, while for symbolic models it's present only if the Output explanations functional parameter is turned on.
For ML models, each item in the array is an object with these properties:-
mlDetails(object): name and value of the feature that determined the prediction. The object has these properties:featureName(string): name of the feature.featureValue(string): value of the feature.
-
positions(array): positions of the text blocks corresponding to the feature. Each array item is an object with these properties: -
sentence(number): index of the source sentence of the feature. type(string): constant ml.
For symbolic models, each item in the array is an object with these properties:
groupBy(number): reserved for future use.-
positions(array): positions of the scope of the extraction rule. Each array item is an object with these properties: -
ruleDetails(array): information about the rules that determined the extraction. Each item of the array is an object with these properties:id(number): zero-based sequence number of the rule.label(string): rule's label, if any.
-
sentence(number): index of the source sentence of the extraction. type(string): constant rule
-
-
geometry(array): geometric information items.
-
namespace(string): name of the software module carrying out the analysis.
extraData
extraData object is s a property of the document object.
In case of a thesaurus model, it has this structure:
"extraData": {
"thesaurusData": {}
}
If normalizeToConceptId is inserted and set to true in the API request to the workflow, then thesaurusData contains detailed information on the extracted concepts, otherwise it's empty.
The option also affects extractions: the value of extracted fields becomes a pointer to a property of the extraData object, for example:
No option or option set to false:
"extractions": [
{
"fields": [
{
name: "concept",
value: "planet"
...
}
...
],
...
},
...
],
"extrdata": {
"thesaurusData": {}
}Option set to true:
"extractions": [
{
"fields": [
{
name: "concept",
value: "12345678"
...
}
...
],
...
},
...
],
"extrdata": {
"thesaurusData": {
"12345678": thesaurus and project data about concept "planet",
...
}
}In case of other models, the value of extraData varies on a case-by-case basis: typically the key contains data only if the model has been produced or modified with Studio, because Studio allows producing this "extra" output via scripting.
knowledge
The knowledge array contains Knowledge Graph information about the syncons referenced, though the syncon properties of their items, in these arrays:
tokensmanSynconsentitiesrelationsitemsin thesentimentobject
The link between those items and the corresponding items in the knowledge array is the value of the the syncon property both have in common.
For example, if this is an item of the tokens array:
{
"atoms": [
{
"end": 45,
"lemma": "basketball",
"start": 35,
"type": "NOU"
},
{
"end": 53,
"lemma": "player",
"start": 46,
"type": "NOU"
}
],
"dependency": {
"head": 2,
"id": 6,
"label": "nmod"
},
"end": 53,
"lemma": "basketball player",
"morphology": "Number=Plur",
"paragraph": 0,
"phrase": 2,
"pos": "NOUN",
"sentence": 0,
"start": 35,
"syncon": 41582,
"type": "NOU"
}
the corresponding entry in the knowledge array could be:
{
"externalIds": [
103665646,
43879
],
"label": "person.basketball_player",
"properties": [
{
"type": "DBpediaId",
"value": "dbpedia.org/page/Basketball_player"
},
{
"type": "WikiDataId",
"value": "Q3665646"
}
],
"syncon": 41582
}
The knowledge array is a reference table: more than one item in the tokens, relations and sentiment arrays can have the same syncon ID, but there's always one entry in the knowledge array for a given syncon (it's a many-to-one relationship).
For example, if a text contains several occurrences of basketball player, each occurrence corresponds to a separate item in the tokens array, but all tokens point to the same entry in the knowledge array.
Items with the syncon property set to -1 have no corresponding entry in the knowledge array. This is because those concepts were heuristically recognized and they are not present in the Knowledge Graph, so there is no previous "knowledge" about them.
The properties of each item of the knowledge array are:
externalIds(array): additional identifiers of the syncon.label(string): textual rendering of the general conceptual category for the syncon in the Knowledge Graph.-
properties(array): it contains the references to external knowledge bases and other user data. Each item has two properties:type(string): name of the knowledge base or that of the user data.value(string): reference in the knowledge base or the value of the user data.
In standard Knowledge Graphs, a syncon can have reference to these knowledge bases:
Name (value of type)Interpretation of the value CoordinateLatitude and longitude WikiDataIdWikipedia article ID DBpediaIdURL of the DBPedia content GeoNamesIdID of the record in the GeoNames database User data are present in customized Knowledge Graphs.
The actual list of knowledge base references and user data found in the items of theknowledgearray can be set with the Required user properties for syncons functional parameter. -
syncon(integer): ID of the Knowledge Graph syncon.
language
The language key, a property of the document object, is present in the output of symbolic models, symbolic steps of ML models and knowledge models.
The key value is the ISO 639-1 code of the document language.
layoutData
The layoutData key, a property of the document object, contains graphical information about the input text. This information is derived or taken from the documentLayout key of the input JSON.
layoutData is an object with these properties:
-
blocks(array): each item is an object that corresponds to a somewhat graphically distinct block of text and has these properties:id(number): identification number of the block in the whole document.page(number): number of the page where the block is located.-
box(array): four items representing the coordinates1 of the bounding box of the text block:- Item 0: upper left corner X
- Item 1: upper left corner Y
- Item 2: lower right corner X
- Item 3: lower right corner Y
-
start(number): position of the first character of the block's text in the overall text of the document. end(number): position of the first character after the block's text in the overall text of the document.
-
fonts(array): same information present in the homonymous key of thedocumentLayoutinput object. -
words(array): each item is an object corresponding to a word of a text block and has these properties:block(number): identification number of the block in which the word is located, it is a reference to an item of theblocksarray and corresponds to theidproperty of that item.-
box(array): four items representing the coordinates1 of the bounding box of the word:- Item 0: upper left corner X
- Item 1: upper left corner Y
- Item 2: lower right corner X
- Item 3: lower right corner Y
-
start(number): position of the first character of the word in the overall text of the document. end(number): position of the first character after the word in the overall text of the document.font(number): identification number of the font with which the word is written, it is a reference to an item of thefontsarray and corresponds to theidproperty of that item.
mainLemmas
The mainLemmas array is a property of the document object.
It contains the text main lemmas.
Each array item is an object that represents a lemma like this:
{
"positions": [
{
"start": 1152,
"end": 1162
},
{
"start": 1163,
"end": 1167
},
{
"start": 1239,
"end": 1249
},
{
"start": 1335,
"end": 1345
},
{
"start": 1394,
"end": 1404
}
],
"score": 6.5,
"value": "locomotive"
}
where:
value(string): lemma.score(number): measure of the lemma importance.positions(array): it contains the positions of the lemma occurrences in the text.
mainPhrases
The mainPhrases array is a property of the document object.
It contains the text main phrases.
Each array item is an object that represents a phrase like this:
{
"positions": [
{
"start": 883,
"end": 903
}
],
"score": 8,
"value": "four-cylinder engine"
}
where:
value(string): phrase.score(number): measure of the phrase importance.positions(array): it contains the positions of the phrase occurrences in the text.
mainSentences
The mainSentences array is a property of the document object.
It contains the text main sentences.
Each array item is an object that represents a sentence like this:
{
"end": 936,
"score": 13.3,
"start": 740,
"value": "The machine is held until ready to start by a sort of trap to be sprung when all is ready; then with a tremendous flapping and snapping of the four-cylinder engine, the huge machine springs aloft."
}
where:
value(string): sentence.score(number): measure of the sentence importance.start (integer): position of the first character of the sentence.end(integer): position of the first character after the sentence.
mainSyncons
The mainSyncons array is a property of the document object.
It contains information about the main Knowledge Graph concepts expressed in the text.
Each array item is an object that represents a Knowledge Graph concept like this:
{
"lemma": "experiment",
"positions": [
{
"end": 224,
"start": 213
},
{
"end": 2830,
"start": 2820
}
],
"score": 5.8,
"syncon": 2496
}
where:
-
The
synconand thelemmaproperties are respectively the outcome of the semantic analysis and the lemmatization.syncon(integer): ID of the Knowledge Graph entry expressed in the text.lemma(string): lemma—or base form—of the concept expression (for example:scarfis the lemma forscarves).
-
score(number): measure of the concept importance in the text. positions(array): it contains the positions of the concept occurrences in the text.
namespaces
The namespaces array is a property of the document object.
It contains resources of the software modules performing the analysis.
Each item of the array lists a namespace's resources and is an anonymous object that can have these properties:
-
categories(array): category tree. Each item of the array corresponds to a node of the category tree and it's an object with these properties:id(string): category ID.label(string): category label.children(array): sub-tree. This property is present only if the category has subcategories. The items of the array are objects corresponding to the subcategories and have the same properties of the parent object, that isid,labeland, possibly,children.
-
extractions(array): list of templates with their respective fields, corresponding to groups and classes in the terminology of Platform extraction projects. Each item is an object that corresponds to the definition of a template and has these properties:name(string): template name.-
fields(array): template fields. Each item is an object corresponding to a template's filed and has these properties:name(string): field name.- (optional)
type(string): the optional attribute of the field.
-
namespace(string): namespace identification code. -
sections(array): list of sections. Each item of the array is an object corresponding to the definition of a section and has these properties:name(string): section name.score(number): numeric part of the basic section's score multiplier or 1 if the basic score is omitted in the definition of the section.
-
segments(array): list of segments. Each item of the array is an object corresponding to the definition of a segment and has this property:name(string): segment name.
options
The options object is a property of the document object.
It can contain the analysis, features and knowledgeProperties arrays that indicate the activities requested from NL core and the outputs it produced. Those arrays reflect output and Apply rules functional parameter of the model block or the corresponding output options in the input JSON, with some exceptions:
- The
analysisarray contains the items disambiguation, entities, categories and extractions when theanalysisarray is missing in the input JSON. disambiguation and entities indicate that NL Core has carried out the basic analysis of the text and named entity recognition, which produce output keyscontent,entities,language,paragraphs,phrases,sentences,tokensandversion.
categories and extractions indicate that thecategoriesand theextractionsarrays are present in the output, but they may contain values only when the functional parameter Apply rules of the model block is turned on. - The
analysisandfeaturesarrays are not present if the arrays of the same name in the input JSON are empty, while theknowledgePropertiesarray is present even if the input array of the same name is empty.
paragraphs
The paragraphs array is a property of the document object.
It contains information about the text paragraphs.
Each array item is an object that represents a paragraph like this:
{
"end": 176,
"sentences": [
0,
1
],
"start": 0
}
where:
start(integer): position of the first character of the paragraph.end(integer): position of the first character after the paragraph.sentences(array): it contains the zero-based indexes of the constituent sentences, whose information is found in thesentencesarray.
phrases
The phrases array is a property of the document object.
It contains information about the text phrases.
Each array item is an object that represents a phrase like this:
{
"end": 65,
"start": 54,
"tokens": [
7,
8,
9
],
"type": "PP"
}
where:
-
type(string): phrase type. Possible types are:Code Description APAdjective Phrase CPConjunction Phrase CRBlank lines DPAdverb Phrase NANot Applicable (usually indicates punctuation) NPNoun Phrase PNNominal Predicate PPPreposition Phrase RPRelative Phrase VPVerb Phrase -
start(integer): position of the first character of the phrase. end(integer): position of the first character after the phrase.tokens(array): it contains the zero-based indexes of the constituent tokens, whose information is found in thetokensarray.
relations
Introduction
Each item of the relations array represents a verb plus the text elements that are in a semantic relation with it. These elements may specify arguments, adjuncts or subordinate clauses.
For example, given this input text:
John sent a letter to Mary.
the relations array can contain an item like this:
{
"verb": {
"text": "sent",
"lemma": "send",
"syncon": 68296,
"phrase": 1,
"type": "",
"relevance": 15
},
"related": [
{
"relation": "sbj_who",
"text": "John",
"lemma": "John",
"syncon": -1,
"type": "NPH",
"phrase": 0,
"relevance": 15
},
{
"relation": "obj_what",
"text": "a letter",
"lemma": "letter",
"syncon": 29131,
"type": "wrk",
"phrase": 2,
"relevance": 10
},
{
"relation": "to_who",
"text": "to Mary",
"lemma": "Mary",
"syncon": -1,
"type": "NPH",
"phrase": 3,
"relevance": 10
}
]
}
Common properties
The verb object and the items of the related array share some properties:
text(string): portion of text corresponding to the element.-
phrase(integer) index of the phrase containing the element. The value must be interpreted as a pointer to an item of thephrasesarray, where the positions of the first and the last character of the phrase can be found. This information can be used for text highlighting.
From the phrase, it is possible to go back to the sentence it belongs to—using thesentencesarray—and from the sentence to the paragraph—using theparagraphsarray—or, going to the opposite direction, to find the tokens contained in the phrase —using thetokensarray.
Subordinate clauses—related items having therelationproperty set tosub—do not have a one-to-one correspondence with a phrase. In that case,phrasehas the conventional value -1. -
syncon(integer) andlemma(string): respectively the outcome of the semantic analysis and the lemmatization. Value -1 forsynconmeans the concept doesn't have a correspondent in the expert.ai Knowledge Graph. This can happen with:- Entities having a proper noun that are heuristically recognized (for example John Smith).
- Parts-of-speech that are not mapped in the Knowledge Graph like pronouns (for example them).
- Subordinate clauses like quotes (for example John said: "I will do it!").
In the first and second cases,
lemmais an empty string. -
relevance(integer): indicator of the importance of the element in the text. Its value ranges from 1 to 15. When the element importance cannot be determined,relevancehas the conventional value -1.
verb
The verb object is always present and it represents the verb.
type is the verb type. When set, it can be one of the following:
| Verb type | Description |
|---|---|
CPL |
to be used as a connection as in John is a smart guy |
MOV |
Verb of movement like to go |
SAY |
Verb of communication like to say |
related
The items of the related array represent text elements related to the verb.
relation is the type of relation and can be one of the following:
Possible values of relation |
|---|
sbj_who |
sbj_what |
obj_who |
obj_what |
is_who |
is_what |
to_who |
to_what |
using_what |
preposition* + _what |
preposition* + _who |
sub** |
when |
where |
to_where |
from_where |
in_where |
which_way |
how |
of_age |
limited_to |
* Prepositions are expressed in the language of the text intelligence engine. For example, a possible value in case of German could be auf_what. Multi-word names of prepositional expressions like according to, in front of, etc., are written in compact form without spaces between words (accordingto, infrontof).
** The sub relation type is used for subordinate clauses.
type identifies the kind of element. Possible values can be uppercase or lowercase. Uppercase corresponds to named entities, lowercase to generic entities.
Relations can be recursive: a related item can be related to another item and so on. In this case, an item of the related array can contain a related array.
For example, given this input text:
Mireille placed the plant pot on the landing at the top of the stairs.
relations can be like this:
"relations": [
{
"related": [
{
"lemma": "Mireille",
"phrase": 0,
"relation": "sbj_who",
"relevance": 14,
"syncon": -1,
"text": "Mireille",
"type": "NPH"
},
{
"lemma": "pot",
"phrase": 2,
"relation": "obj_what",
"relevance": 15,
"syncon": 18506,
"text": "the plant pot",
"type": "prd"
},
{
"lemma": "landing",
"phrase": 3,
"relation": "on_what",
"relevance": 5,
"syncon": 16859,
"text": "on the landing",
"type": "bld"
},
{
"lemma": "top",
"phrase": 4,
"related": [
{
"lemma": "stairs",
"phrase": 5,
"relation": "of_what",
"relevance": 1,
"syncon": 20016,
"text": "of the stairs",
"type": "bld"
}
],
"relation": "at_what",
"relevance": -1,
"syncon": 37732,
"text": "at the top",
"type": ""
}
],
"verb": {
"lemma": "place",
"phrase": 1,
"relevance": 15,
"syncon": 68498,
"text": "placed",
"type": ""
}
}
]
sections
The sections array contains the data of the text sections specified in the request, with possibly modified positions due to differences between input text and analyzed text.
Each item in the array has this format:
{
"namespace": (string) namespace,
"name": (string) section name,
"positions": [
range(s)
]
}where:
namespace(string): name of the software module carrying out document classification inside the text intelligence engine.name(string): name of the section.-
positions(array): it indicates the range (or ranges) of characters that make up the section. Each item of the array is an object with this format:{ "start": (integer) zero-based position of the first character in the section "end": (integer) zero-based position of the first character after the section }
For example:
"sections": [
{
"namespace": "iptc_en_1.0",
"name": "TITLE",
"positions": [
{
"start": 0,
"end": 4
}
]
},
{
"namespace": "iptc_en_1.0",
"name": "BODY",
"positions": [
{
"start": 6,
"end": 10
}
]
}
]
segments
The segments array is a property of the document object.
It contains information about the segments defined in the imported CPKs that are generated with expert.ai Studio.
It has a structure like this:
"segments": [
{
"name": "SEGMENT1",
"namespace": "segments",
"positions": [
{
"end": 137,
"start": 0
},
{
"end": 477,
"start": 250
}
]
},
{
"name": "SEGMENT2",
"namespace": "segments",
"positions": [
{
"end": 137,
"start": 0
},
{
"end": 577,
"start": 479
}
]
}
]
sentences
The sentences array is a property of the document object.
It contains information about the text sentences.
Each array item is an object that represents a sentence and has a structure like this:
{
"end": 66,
"phrases": [
0,
1,
2,
3,
4,
5
],
"start": 0
}
where:
start(integer): position of the first character of the sentence.end(integer): position of the first character after the sentence.phrases(array): it contains the zero-based indexes of the constituent phrases, whose information is found in thephrasesarray.
sentiment
The sentiment object contains three scores indicating the tone of the whole text:
positivity(number): amount of positivity.negativity(number): amount of negativity.overall(number): overall sentiment score, which is a combination of the scores above.
All sentiment scores are expressed in a range from -100 (extremely negative) to 100 (extremely positive).
The sentiment object contains an items array whose elements, in turn, can contain nested items arrays. These items represent the clusters of text elements that give a positive or negative contribution to the sentiment.
For example, given this input text:
The road was bad.
items clusters can be like this:
"items": [
{
"lemma": "road",
"sentiment": -7,
"syncon": 19001,
"items": [
{
"lemma": "bad",
"sentiment": -7,
"syncon": 81195
}
]
}
]
sentiment (number) is the sentiment score of the cluster or leaf-item. The sentiment score of a cluster is a function of the child items' scores and the possible modifiers, which are not returned as separate items, but are nevertheless taken into account.
Take, for example, a slight change introduced in the sample text:
The road was really bad.
the really modifier makes the score worse:
"items": [
{
"lemma": "road",
"sentiment": -8.8,
"syncon": 19001,
"items": [
{
"lemma": "bad",
"sentiment": -8.8,
"syncon": 81195
}
]
}
]
On the other hand, a not before bad can invert the sentiment polarity from negative to positive. The sentiment value can be zero.
The syncon (integer) and lemma (string) properties are respectively the outcome of the semantic analysis and the lemmatization.
An item having nested items can be an "unnamed cluster": in that case, the lemma property is an empty string.
If the intrinsic item polarity—positive or negative—is opposite to that of the paragraph it belongs to, this marker:
[*]
is added as a suffix to the the lemma.
For example, given this input text:
The road was not bad.
The lemma bad is marked with the "opposite polarity" sign because it is negated by not:
"items": [
{
"items": [
{
"lemma": "bad[*]",
"sentiment": 7,
"syncon": 87597
}
],
"lemma": "road",
"sentiment": 7,
"syncon": 19001
}
]
Another possibility occurs when a lemma "attracts" other words in the same phrase. For example, given the input text:
Michael Jordan was one of the best basketball players of all time. Scoring was Jordan's stand-out skill, but he still holds a defensive NBA record, with eight steals in a half.
a value of lemma could be:
stand-out;skill
In this case the merged terms are separated by a semi-colon (;).
Value -1 for syncon means the concept doesn't have a correspondent in the expert.ai Knowledge Graph.
tags
tags is an array containing the tag instances. Tags can be produced by models generated with Studio.
Each item of the array has the following properties:
level(integer): one of the levels on which tag instances seat.namespace(string): name of the software module carrying out tag identification.-
tags(array): it contains the tag instances that seat in the level. Each item of the array has these properties:startandend(integer): start and end position of the text corresponding to the tag instance.-
explanations(array): it contains information about the origin of the tag instances. It's present only if the Output explanations functional parameter is turned on. Each item contains:-
type(string): the origin of the tag instance. It can have these values:- rule if the instance has been generated by tagging rules.
- ruleScript if the instance has been generated by JavaScript.
- documentData if the instance comes from input
documentData.
-
ruleDetails(array): available iftypeis set torule. It has these properties:id(integer): rule id.label(string): optional rule label.
-
-
geometry(array): it contains geometric references, each item of which represents a rectangular area (a box) containing text. See below for further details about its parameters. grammarType(string): grammar type associated to the tag.removed(boolean): If set totrue, it means the tag instance has been flagged as "negative" with JavaScript, but is still available.score(number): reserved for future usesyncon(integer): syncon ID associated to the tag in its declaration.tagName(string): tag name.value(string): it is the so called tag entry, that is the textual value of the tag instance. It can be the literal text betweenstartandendor the result of the normalization/transformation of it.
tokens
The tokens array is a property of the document object.
It contains information about the tokens in which the text was divided during the analysis.
A token is either a single word, a collocation or punctuation.
Each array item is an object that represents a token like this:
{
"atoms": [
{
"end": 24,
"lemma": "credit",
"start": 18,
"type": "NOU"
},
{
"end": 29,
"lemma": "card",
"start": 25,
"type": "NOU"
}
],
"dependency": {
"head": 2,
"id": 4,
"label": "obj"
},
"end": 29,
"lemma": "credit card",
"morphology": "Number=Sing",
"paragraph": 0,
"phrase": 2,
"pos": "NOUN",
"sentence": 0,
"start": 18,
"syncon": 54956,
"type": "NOU"
}
where:
syncon(integer): outcome of the semantic analysis process. Its value is the ID of the corresponding entry in the Knowledge Graph or -1 if there's no corresponding entry.type(string): type label.lemma(string): result of the lemmatization. It is the lemma—or base form—of the token text, for example:scarfis the lemma forscarvesandbeis the lemma forwas.pos(string): result of part-of-speech tagging, the process that marks up each token with the corresponding Universal POS tag.-
dependency(object): result of syntactic analysis, the parsing process that detects the universal dependency relation between each token and the sentence root token or another token.The process assigns a dependency relation label to each token.
For example, for this sentence:The company has developed an entirely new category of products.syntactic analysis determines the head token index and the dependency label as follows:
Token index Token text Head token index Universal dependency label 0 The1 det1 company3 nsubj2 has3 aux3 developed3 root4 an7 det5 entirely7 advmod6 new7 amod7 category3 obj8 of9 case9 product7 nmod10 .3 punctDependencies can be represented in various ways, such as a tree or arrow arcs.
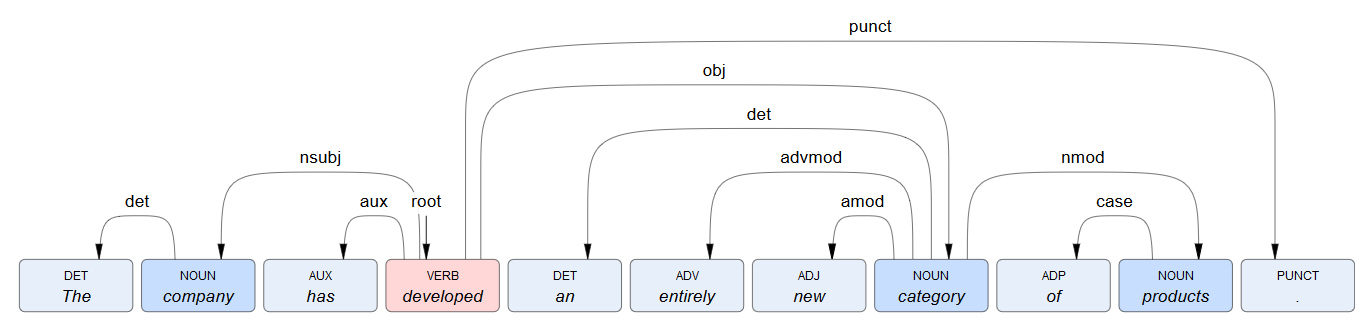
Inside
dependency:id(integer): index of the token in the text.dep(string): it specifies the dependency relation with another token according to the Universal Dependencies conventions.head(integer): it identifies the token that receives the relation. Its value corresponds to the value of theidproperty of another token, the only exception being the root token—the one with thedepproperty set toroot—for whichheadandidhave the same value.
-
morphology(string): result of morphological analysis, the process that determines lexical and grammatical features of each token in addition to the part-of-speech.The result of the analysis is a list of Universal features.
For example, the morphological analysis of the first token of this sentence:
I saw a dandelion on my lawn.gives:
Case=Nom|Number=Sing|Person=1|PronType=Prswhich is a list of feature-value pairs corresponding to:
Pair Feature label Feature description Value label Value description Case=NomCaseCase NomNominative Number=SingNumberNumber SingSingular Person=1PersonPerson 1First PronType=PrsPronTypePronoun type PrsPersonal -
start(integer): position of the first character of the token. end(integer): position of the first character after the token.phrase(integer): phrase containing the token; it's the zero-based index of the phrase in thephrasesarray.sentence(integer): sentence containing the token; it's the zero-based index of the sentence in thesentencesarray.paragraph(integer): paragraph containing the token; it's the zero-based index of the paragraph in theparagraphsarray.-
In case of collocations—for example: credit card—, the token object can contain the
atomsarray. It contains an item for every word of the collocation and has these properties:type(string): type label for the word.lemma(string): lemma of the word.start(integer): position of the first character of the word.end(integer): position of the first character after the word.
If the semantic analysis recognizes a token as a named entity—for example: a person's name—without a corresponding entry in the Knowledge Graph, syncon is set to -1 and the token object has an additional vsyn (virtual syncon) property like this:
{
"syncon": -1,
"vsyn": {
"id": -436106,
"parent": 73303
},
"start": 0,
"end": 19,
"type": "NPR.NPH",
"lemma": "Mauricio Pochettino",
...
vsyn (object) has these properties:
id(integer): negative number assigned to all tokens considered as occurrences of the same entity. It is not the ID of a Knowledge Graph entry.parent(integer): ID of the Knowledge Graph entry which, conceptually, is the parent of the concept expressed by the token. For example, if the token has been recognized as a person's name,parentis the ID of the concept person.
topics
The topics array is a property of the document object.
It lists the Knowledge Graph topics the text is about.
Each array item is an object that represents a Knowledge Graph topic like this:
{
"id": 223,
"label": "mechanics",
"score": 3.5,
"winner": true
}
where:
id(integer): topic ID.label(string): topic name.score(number): measure of the text topic importance.winner(boolean): set totrueif the topic is considered particularly important.
version
The version key is a property of the document object.
The key value is the software module version that performed the analysis.
Type labels
The labels below are used for the type property of tokens and tokens' atoms.
| Code | Description |
|---|---|
ADJ |
Adjective |
ADV |
Adverb |
ART |
Article |
AUX |
Auxiliary verb |
CON |
Conjunction |
NOU |
Noun |
NOU.ADR |
Street address |
NOU.DAT |
Date |
NOU.HOU |
Hour |
NOU.MAI |
Email address |
NOU.MEA |
Measure |
NOU.MON |
Money |
NOU.PCT |
Percentage |
NOU.PHO |
Phone number |
NOU.WEB |
Web address |
NPR |
Proper noun |
NPR.ANM |
Proper noun of an animal |
NPR.BLD |
Proper noun of a building |
NPR.COM |
Proper noun of a business/company |
NPR.DEV |
Proper noun of a device |
NPR.DOC |
Proper noun of a document |
NPR.EVN |
Proper noun of an event |
NPR.FDD |
Proper noun of a food/beverage |
NPR.GEA |
Proper noun of a physical geographic feature |
NPR.GEO |
Proper noun of an administrative geographic area |
NPR.GEX |
Proper noun of an extra-terrestrial or imaginary place |
NPR.LEN |
Proper noun of a legal/fiscal entity |
NPR.MMD |
Proper noun of a mass media |
NPR.NPH |
Proper noun of a human being |
NPR.ORG |
Proper noun of an organization/society/institution |
NPR.PPH |
Proper noun of a physical phenomena |
NPR.PRD |
Proper noun of a product |
NPR.VCL |
Proper noun of a vehicle |
NPR.WRK |
Proper noun of a work of human intelligence |
PNT |
Punctuation mark |
PRE |
Preposition |
PRO |
Pronoun |
PRT |
Particle |
VER |
Verb |
Unlike Universal POS tag, used for the pos property of tokens, type labels combine part-of-speech information with entity type information and also apply to atoms.
Positions
The output of symbolic models and symbolic steps of ML models contains the position of text blocks (for example paragraphs, sentences, phrases, parts of text that "explain" predicted categories or extractions, named entities, text tokens, words, lemmas).
All these positions are referred to the content property of the document object.
The starting position is returned in the start property and the ending position in the end property.
The value of the start property is the zero-based index of the first block character.
For example, if the text is:
Michael Jordan was one of the best basketball players of all time.
the start position of the phrase of all time is 54:
Michael Jordan was one of the best basketball players of all time.
↑
01234567890123456789012345678901234567890123456789012345678901234567890
0 1 2 3 4 5 6 7The value of the end position is the zero-based index of the first character after the text block.
In the example above, the end position of the phrase is 65:
Michael Jordan was one of the best basketball players of all time.
↑
01234567890123456789012345678901234567890123456789012345678901234567890
0 1 2 3 4 5 6 7Geometry
The positions of the text that explain the predictions of the model can sometimes be enriched with geometric information.
This can occur only if the input to the model is the text of the document to be analyzed together with its graphic layout, an information that is conveyed to the model in input key documentLayout, for example when, in the workflow, the model block is preceded by a block of the Extract Converter processor.
The geometric information is like this:
"geometry": [
{
"box": [
556,
443,
597,
457
],
"page": 7,
"pageHeight": 1170,
"pageWidth": 827
}
]
where:
-
geometry(array): geometric references, each item of which represents a rectangular area (a box) containing text and has these properties:-
box(array): four items representing the coordinates1 of the box:- Item 0: upper left corner X
- Item 1: upper left corner Y
- Item 2: lower right corner X
- Item 3: lower right corner Y
-
page(integer),pageHeight(integer),pageWidth(integer): respectively, the number, height and width of the page where the box is located.
-
Coordinates and sizes are in pixels and referred to a 100 DPI (dots per inch) rendering of the page. The coordinates origin is at the top left corner of the rendered page.