Simple Remapper
Overview
Simple Remapper is a remapper that, unlike Foreach and like a splitter, generates items on which the blocks of its context then iterate. But while a splitter creates items by splitting its input, Simple Remapper create items by aggregating consecutive items of a previous context.
The reference context can be that of a splitter or of another remapper.
Input
A Simple Remapper block has a virtual input that is the output of upstream blocks. These blocks can be those of the reference context or out-of-context blocks. In the first case, there are multiple outputs per block, one per context iteration.
Block properties
The properties of a Simple Remapper block are accessed by editing the block and are divided into these groups:
-
Basic properties:
- Block name
- Component version (read only)
- Block ID (read only)
-
Functional:
- Context to reduce: the reference context from which input items are taken. It is chosen with a drop-down. To remove the choice, select Clear
 .
. - Keep same context: read-only, always off. It's a reminder that Simple Remapper, unlike Foreach, creates it's own, new, context.
-
Remapping strategy: the technique Simple Remapper uses to aggregate consecutive input items. It's based on:
- The value of the input item's category field, which is specified in Field name for item category (see below).
-
The value of this parameter, which can be chosen between:
- Begin Marker: a new output item is created whenever the category of the input item has literal value Begin.
- Same Category: each output item represent all the consecutive input items with the same value of the category field.
-
Field name for item category: the name of the key in the input items representing the category of the item. It is used to enact the remapping strategy (see above).
- Report items on output: whether or not to include in each output item an
itemsarray containing the zero-based indexes of all the consecutive input items the output item aggregates. - Field name for the output array: name of the array inside each output item containing the data of the aggregated input items. Each output item will contain this array and the array will contain one object for each aggregated input item. The object will contain the keys specified in the Input tab of the properties pop-up (see below).
- Context to reduce: the reference context from which input items are taken. It is chosen with a drop-down. To remove the choice, select Clear
-
Deployment:
- Timeout: execution timeout expressed in minutes (m) or seconds (s).
- Replicas: number of required instances.
- Consumer Number: number of threads of the consumer, the software module of the block that provides input to process by taking it from the block's work queue.
- Memory: required memory.
- CPU: thousandths of a CPU required (for example: 1000 = 1 CPU).
-
Input: the keys to consider in input items, each mapped to a name. The category field for remapping strategy (see above) must be included in this map. This map also allows defining other possible keys to include in the object that represents an input item in the array specified in Field name for the output array.
See below how to define this map. -
Output: read-only, a reminder of the structure of the output objects that are produced.
If the remapping strategy is Same Category, then the first key of each output item will be the category.
Then, the output object will contain the array specified in Field name for the output array. This array will contain objects whose keys are those defined in the input map.
Finally, if the Report items on output option is turned on, the output object will contain theitemsarray with the numeric indexes con the consecutive input items aggregated in the output object.
Defining the map
To map the keys of input items to consider, edit the block and go in the Input tab, then:
-
To add a new mapping, in the Input tab of the properties pop-up:
- Click the plus button: a new row is added below the list of existing mappings.
- In the left field enter a name of your choice.
-
Using the drop-down choose a the corresponding input item key from the list of the output keys of the upstream blocks.
First of all select the type of the property choosing between number, string, boolean, object and array. After that, the list below will only show output keys of the same type.
The list is divided in groups, one group for each suitable upstream block. Select the name of the block multiple times or the expand and collapse icons to the right of the block name to show or hide the sub-list of output keys for that block.
If the type of the property is object, the first entry in the sub-list is the block name.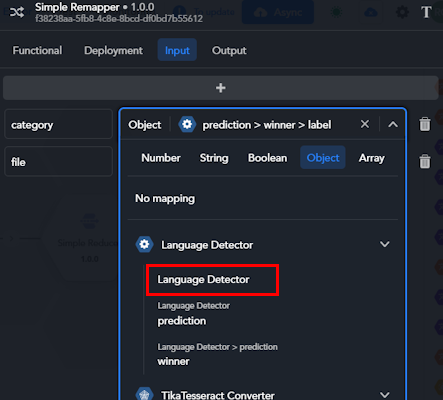
By choosing it, you indicate that the value of the mapped key will coincide with the entire output JSON of that block.
Note
The drop-down list shows all the first-level keys that can, potentially, be available, but the keys that are actually there when executing the workflow may be less. If you map a key that's not actually produced at runtime, the corresponding output object will be set to
null.You can filter the list by typing at the top of it: the list will show only keys with matching names.
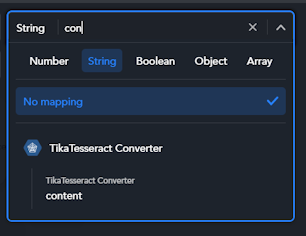
To cancel the mapping process, select No mapping from the list or, if you already chose a key, select Clear
.
-
To modify an existing mapping:
- Edit the left field to change the name of the mapped key.
- Use the drop-down as described above to choose a different input key.
-
To remove an existing mapping, select Remove
 to the right of it.
to the right of it.
When done, select Confirm.
Output
A Simple Remapper block produces as many output items as the groups determined by the remapping strategy. The block's context cycles over these items.
Each item is a JSON object with the structure displayed in the Output tab of the properties pop-up.
As with splitters and other remappers, the output of the End Context block that must be placed to mark the end of the context is an empty object and the context output must be "pulled out" of it using a reducer.