Text Fragmenter processor
Description
The Text Fragmenter breaks the input text into fragments such as sentences, newline separated parts and quotes.
Input
The processor requires the input JSON to contain at least this top level key:
"text": "text"
An optional top level key is:
"options": options
where:
textis the text to process.-
optionsis an object. Its properties can be used to override the values of block's functional properties (see below). This is the correspondence between the properties ofoptionsand the functional properties of the block:Object property Corresponding functional parameter outputTextPropagate input text to output
Block properties
Block properties can be set by editing the block.
Text Fragmenter workflow blocks have the following properties:
-
Basic properties:
- Block name, it can be edited
- Component version (read only)
- Block ID (read only)
-
Functional:
- Propagate input text to output: when turned on, the input key
textis echoed in the output JSON. Default: off.
- Propagate input text to output: when turned on, the input key
-
Deployment:
- Replicas: number of required instances.
- Memory: required memory.
- CPU: thousandths of a CPU required (for example: 1000 = 1 CPU).
-
Type Specific:
- Timeout: execution timeout expressed in minutes (m) or seconds (s).
-
Input
These properties correspond to the top level key of the input JSON.
They need to be set only when input mapping is necessary. -
Output: read-only, this property is a navigable description of the structure of the output array.
Output and output-input mapping
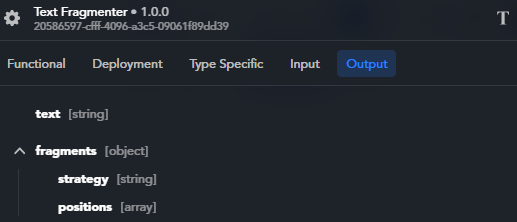
The output of a Text Fragmenter block is a JSON object with the following structure:
{
"fragments": {}
}
The fragments object has these properties:
strategy(string): fragmentation strategy used, for example BaseTextFragmenter. It is a troubleshooting only information.-
positions(array): array of objects, each corresponding to the extremes of a fragment. Each object has these properties:start(number): the zero-based position of the first character of the fragment in the text.end(number): the zero-based position of the first character after the fragment in the text.
A Text Fragmenter block is suitable to be followed by a Language Detection block because the latter is able to accept fragments as input to make specific predictions about them as well.
For a correct functioning of the two processors in pairs:
- Turn on the Propagate input text to output functional property of the Text Fragmenter block.
-
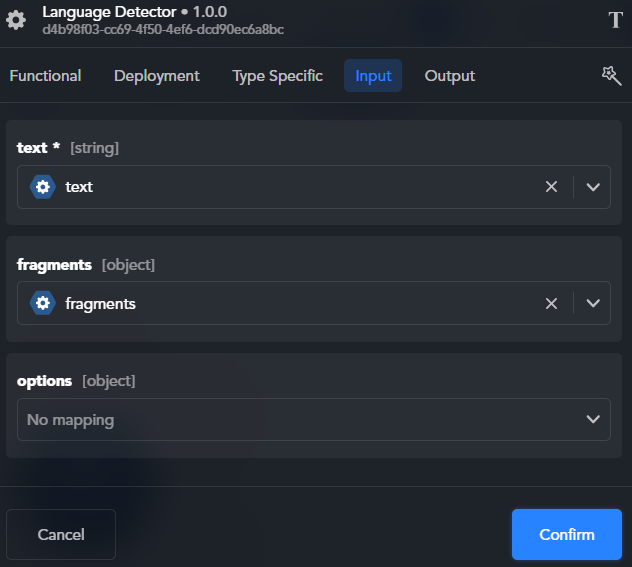
In the Language Detector block, associate input properties
text *andfragmentsto the homonymous output keys of the Text Fragmenter block.