Advanced topic: record generation process
Introduction and definitions
The process that begins with capturing data and then returning it as an aggregated record is complex and comprised of many steps. What follows is the description of the process that transforms single extracted tokens into complex records.
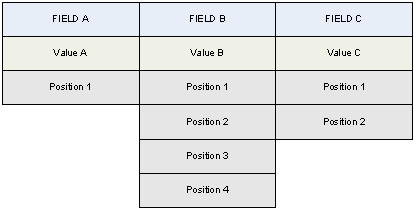
Each extracted token is coded with information about its:
- Value: what was extracted in a given field.
- Position: where in the input document it was extracted.
- Template and Field: the data "destination".
Groups of values extracted by a single rule represent the first available records.
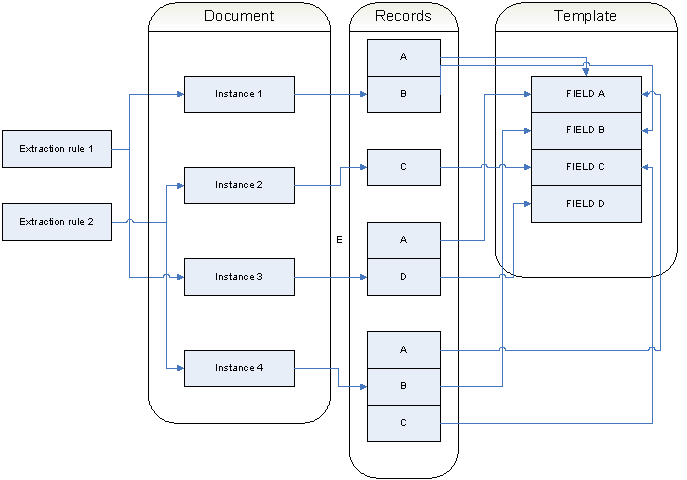
When a single rule identifies several values for a single field in a table, more records are generated.
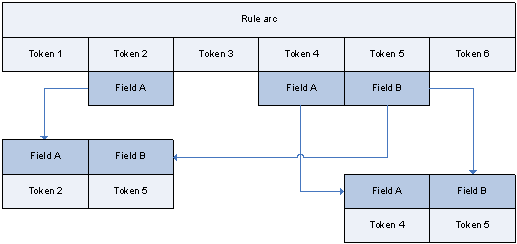
Simple record
At this stage, a record consists of a set of identical values which refer to the same template and the same field. Each value is associated to a list of positions that identify all occurrences of the given value that was aggregated to the given field.
For the sake of convenience, the records are divided into different groups based on their characteristics:
- Different records with the same destination template are called cognate.
- Cognate records that do not have any field in common are called compatible.
- Cognate records that have one field in common are named consistent if such field contains the same value, or inconsistent in the opposite case.
- Cognate records that have several fields in common are consistent if all the fields in common have the same value.
- If a record is consistent with another record and all of its fields are in common with the latter, then the former is said to be reducible to the other record.
- If a reducible record has at least one position for each field in common with the reducing record, it is said to be contained within the reducing record.
The process
The phases
The extraction records elaboration process is divided into two main phases:
- Bundling
- Joining
Phase 1 - Bundling
Definition
The first phase of the extraction records elaboration process is called bundling. During this phase, the number of records is reduced whenever possible. This is true when the fields of a record are a sub-set of another record's field; in this case, the first record can be bundled into the second one. At the end of this process, the list of positions of the second record is the combination of the positions of the two original records.
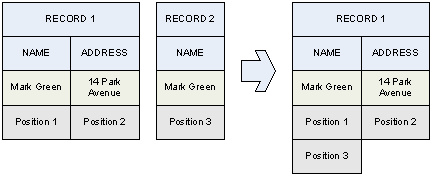
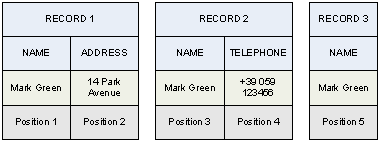
In case of ambiguity, when there are two records that can potentially receive the data of another one, it is not possible to perform any reduction. In the following example, record 3 may be bundled both with 1 and 2, therefore it is not deleted.
The algorithm
Bundling is carried out following these steps:
- Records are arranged from the longest to the shortest. Starting from the first, each record is compared to the previous one, thus calculating a list of the records which can "absorb" other records. A record can be absorbed when it contains a number of fields less than—or equal to—the number of the fields contained in the other record, and both the fields and the associated values are the same.
- Due to the order of progression, two records from the same "absorption" list can never absorb each other.
- If the list is not empty and only has one value, it means that the record is absorbable, and therefore it is absorbed. This will cause the record to be deleted, while the absorbing record adds all of the positions from the absorbed record to its list.
- If the list has several values, the positions must be verified, especially when one of the absorbing records has the same positions as the absorbable record. If no absorbing record has this feature, nothing will happen. Otherwise, all absorbing records will absorb the absorbable records.
- When all the fields of the second record have the “S” attribute, then the condition of the positions must be verified for the record to be absorbed.
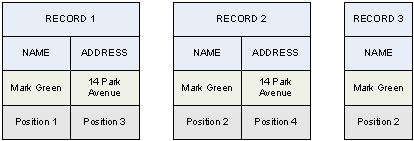
The following table illustrates how the impossibility of bundling record 3 to one of the other two records is only apparent, since they are indeed identical and can be reduced to a single record by removing all forms of ambiguity.
Another form under which an apparent ambiguity may occur is the following:
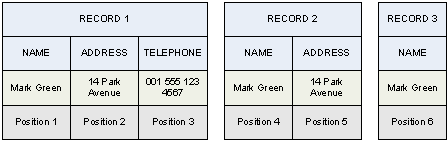
Record 3 cannot be immediately bundled with 1 or 2 because they can both absorb it. Actually, record 1 can also be bundled with 2, thus eliminating every ambiguity, and then also be bundled with record 3 later.
Please consider the following situation as well:

Record 4 is really ambiguous, because it could be bundled both with 2 and 3, therefore, it can not be absorbed by either of them. However, if an additional record such as the following is also present:
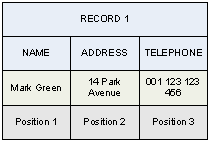
Everything could be solved because, first, records 2 and 3 would be absorbed by record 1, and then, the latter will also absorb record 4.
Phase 2 - Joining
Definition
The second phase of the extraction records elaboration process is called joining. During this phase pairs of records are combined in respect to the cardinal fields. At the end of this process, every new generated record will contain the combination of fields with their values, each with all the positions that were present in the original instances.
In this process, the programmed scope does not play any role: if a combination is possible, it will be done regardless of the positions of the values.
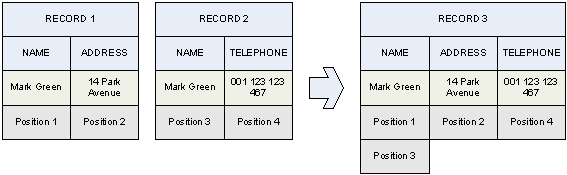
A generated record can also be re-used as a generating one.
The algorithm
All records that can be joined are joined. This may lead to the generation of double records or records contained in bigger ones. Therefore, at the end of the joining phase, a new bundling process is performed and only the remaining records are maintained.
Assume that the following four records have been extracted:

The following joining processes are generated:
AB + BC = ABC
BC + CD1 = BCD1
BC + CD2 = BCD2
ABC + CD1 = ABCD1
ABC + CD2 = ABCD2
By performing a new bundling process, the two longest combinations from the list of records (both original and generated) will progressively "absorb" the others until only they remain. The list of records:
ABCD1
ABCD2
BCD1
BCD2
ABC
AB
BC
CD1
CD2
Undergoes a bundling process so that the final output is:
ABCD1
ABCD2
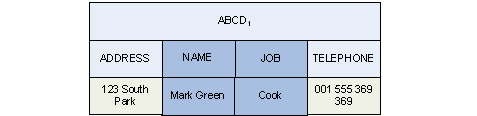
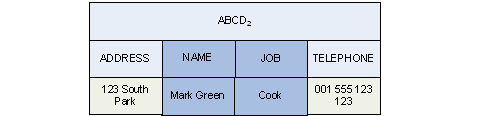
In this context, the bundling mechanism uses the positions associated with the fields less strictly. In the current implementation it is still used when stating that a record can be absorbed when there is no intersection between the lists of field positions in both records.
Distribution
The use of cardinal fields is distributive. Consider the following example, where:
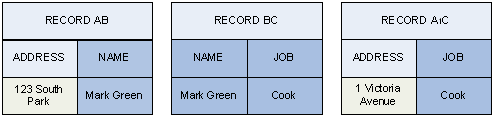
produces:
AB + BC = ABC
BC + A1C = A1BC
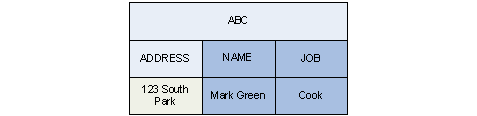
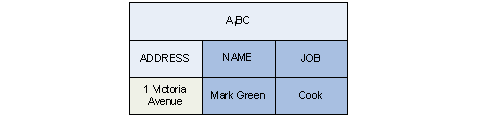
BC is joined to both of the two other blocks. The following example:
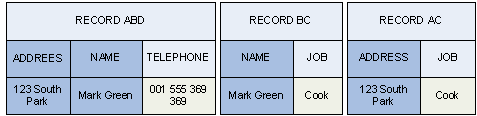
produces:
ABD + BC = ABCD
ABD + CD = ABCD
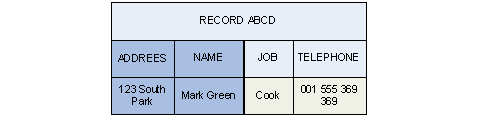
which can be bundled. On the other hand, two values for D would have produced two records ABCD1 and ABCD2.
Complex Record
At the end of this process, a record consists of a set of values which refer to one or more different fields belonging to the same template and have consistently been aggregated based on the options previously set for the fields and the template themselves.
For example, for a sample called PERSONAL_DATA (whose aim is to aggregate personal information related to names of people present in a document), the records could look like the following:
| PERSONAL_DATA | |||
| NAME | ADDRESS | TELEPHONE | |
| Record 1 | John Smith | 34 Park Avenue | 555 123-4567 |
| Record 2 | Sarah Parker | 1280 Stanstead Rd | 555 369-369 |
| Record 3 | Laura Diaz | 12 Square Garden |
Note
All fields defined in a template may not always be present (along with their value) in the final record.