Tagging
Introduction
Tagging allows you to associate a label and possibly an additional syncon ID to selected text atoms. This additional information can be used in rules and scripting.
The screenshot below shows how tags used to label the rainbow colors cited in the text are displayed in Studio.

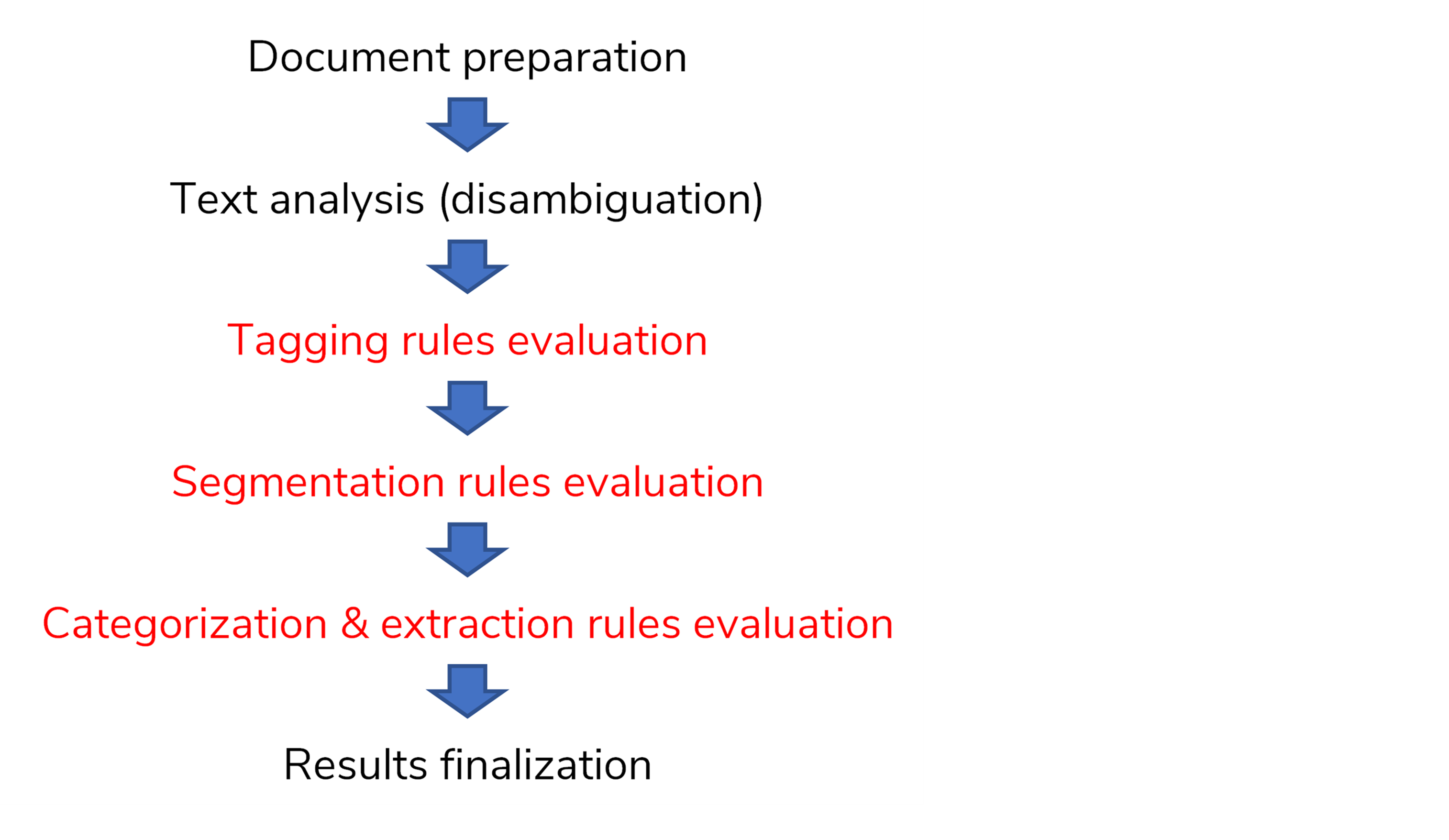
Tagging takes place after the disambiguation and before the evaluation of categorization and extraction rules.
There are two complementary ways to tag atoms: by rules and by script.
The final result is a combination of the two, because the event-handling functions by which you can work on tags within the script—onTagger and onTaggerLevel—are evaluated after the evaluation of tagging rules, so they can change the results of rules activation.
Tagging rules are the first to be evaluated among all the other rules so that segmentation, categorization and extraction rules can refer to tags.
Tagging by rules
First: declaration
Tagging by rules is a two-step process.
In the first step, tags are declared in the config.cr file.
The syntax is:
TAGS
{
@tag1Label,
@tag2Label:tag2SynconID
}Tags can be declared in two different ways, based on their purpose:
- By only specifying their label, as for
@tagLabel_1in the syntax above - By specifying the label and a syncon ID, as for
@tag_Label2:tagSynconIDin the syntax above
The tag label, once applied to an atom, becomes an additional attribute. Multiple tags can be applied to the same atom, they accumulate one on top of the other.
The syncon ID, on the other hand, if specified, replaces the original syncon ID.
Second: rules
The second step is to define tagging rules. Similar to an extraction rule, when the condition is met and the rule is triggered, the portion of text that matches the attribute in square brackets is tagged with the tag label and the syncon ID, if any.
The syntax is:
SCOPE scopeOption
{
TAGGER(tagLevel)
{
@tagLabel[attribute]
}
}where tagLevel is the level of the generated tags. It is a positive inter number. It can be omitted, in which case its default value is 10000.
The value determines the order in which the rule is evaluated: the higher the value, the later the rule will be evaluated.
For instance, if you have a rule with TAGGER() and a rule with TAGGER(1), the latter will be evaluated before.
This means that tags defined by mean of TAGGER(1) rules can further be used or manipulated by the TAGGER() rules.
Note
To generate a tag that is associated with a syncon ID it is sufficient to refer to the tag label, since the syncon ID is determined by the tag's declaration.
The level also represents the layer on which the tag is located: multiple tags for the same atom can coexist on different layers.
Using tags
Tags can be referenced in rules with the TAG attribute or by their syncon ID, if any.
The next example illustrates both possibilities.
Suppose the goals are:
- Extraction: tag all drug codes present in a text in order to easily extract them as one thing.
- Categorization: improve the results by manipulating the assigned ID for lemma drug (e.g. for some projects, polysemy may not be an issue to solve).
The first step is declaring the tags:
TAGS
{
@CODE,
@MEDICINE:100012140//@SYN: #100012140# [drug]
}
@CODE will be used as a pure label while @MEDICINE will simultaneously attach the tag label and replace the token syncon ID with 100012140.
The second step is defining the tagging rules:
SCOPE SENTENCE
{
TAGGER()
{
@CODE[PATTERN("\d{8}")] // Every eight digit number will be tagged as CODE.
}
TAGGER()
{
@MEDICINE[LEMMA("drug")] // every occurrence of lemma drug (regardless of its meaning) in a text will be tagged as MEDICINE and will be assigned syncon ID 100012140
}
}
If the above rules are run against this text:
Ibuprofen Hs Code is 29420012.
The use of this drug is not recommended in patients with advanced renal disease.
the numerical string in the semantic analysis will be tagged with the label CODE.
The lemma drug meaning changes from syncon 100008386 (drug in the sense of narcotic) to syncon 100012140 (medicine).
At this point, the categorization and extraction rules can leverage the information derived from the tagging.
The following categorization rule will generate a hit in the sample text thanks to the tagger manipulation of the meaning of drug:
SCOPE SENTENCE
{
DOMAIN(dom1)
{
SYNCON(100012140)
}
}
The following extraction rule will generate a hit by simply stating the desired TAG :
SCOPE SENTENCE
{
IDENTIFY(TEST)
{
@DRUG_CODE[TAG(CODE)]
}
}
Declaring the same tag multiple times
Like normal extraction rules, where you can repeat the same extraction field multiple times, it is possible to repeat the same tag multiple times in a tagging rule, for example:
TAGGER()
{
@DATE[LEMMA("until")]
<:2>
TYPE(ART)
<:2>
@DATE[TYPE(DAT)]
}
Tagging on atomic level
When using tags by rules, there may be a situation in which a tagged element corresponds to an atom of a collocation.
For example, consider this simple tag:
TAGGER()
{
@ANIMALS[KEYWORD("dog", "dogs")]
}
and the following rule:
SCOPE SENTENCE
{
IDENTIFY(DAMAGES)
{
@DOG_DAMAGE[TAG(ANIMALS)]
}
}
applied to this input text:
The dog bite on Lucy's hand is still visible.
You will get, thanks to the tagger, the following output.

As you can see, the tag triggers inside the collocation dog bite, but only the atom dog is tagged.
This situation occurs when defining tags with one of these attributes:
If you want to tag the whole collocation, you have to use the TOKEN transformer.
If you change the rule above in this way:
SCOPE SENTENCE
{
IDENTIFY(DAMAGES)
{
@DOG_DAMAGE[TAG(ANIMALS)]|[TOKEN]
}
}
and you apply it to the same text, you will get:

Tag merging
When a single tag has more rules, a tagging rule can lexically overlap with the other ones. In this case, all tags are merged into a single one.
For example, consider this tag:
TAGS
{
@MYTAG1
}
and the following tagging rules:
SCOPE SENTENCE
{
TAGGER(10)
{
@MYTAG1[KEYWORD("had a good time")]
}
TAGGER(10)
{
@MYTAG1[KEYWORD("a good")]
}
TAGGER(10)
{
@MYTAG1[KEYWORD("good time")]
}
}
If these rules are applied to this text:
I went to Sweryth and I had a good time.
you will get in the Semantic Analysis tool window:

The first tagging rule fully overlaps with the other two. In this case, the longest tag is kept.

Consider another example:
SCOPE SENTENCE
{
TAGGER(10)
{
@MYTAG1[KEYWORD("good time")]
}
TAGGER(10)
{
@MYTAG1[KEYWORD("a good")]
}
}
applied to this text:
I went to Sweryth and I had a good time.
You will get in the Semantic Analysis tool window:

As you can see, both tagging rules partially overlap on the token good and a new single tag is therefore created.

The overlap is also managed in case of different tag levels.
For example:
SCOPE SENTENCE
{
TAGGER(10)
{
@MYTAG1[KEYWORD("a good")]
}
TAGGER(10)
{
@MYTAG1[KEYWORD("good time")]
}
TAGGER(20)
{
@MYTAG1[KEYWORD("had a good time")]
}
}
In this case, there is a two-step merge:
-
The two level 10 tags are merged into one.

-
The level 10 tag overlaps with the level 20 tag and the former is merged into the latter.

In fact, if you apply these rules to this text:
I went to Sweryth and I had a good time.
You will see in the detail area on the right of the Semantic Analysis tool window:
| Had | A | Good | Time |
|---|---|---|---|
 |
 |
 |
 |
As you can see, all tokens are part of the new level 20 tag.
Tagging partial or whole textual sequences
Tagging occurs on textual elements defined in the tagging rule through the tag definition.
You can use tags for:
- Single textual elements.
- Whole textual sequences.
- Partial textual sequences.
For single textual elements, see the example above.
In case of whole textual sequences, you can use the SEQUENCE transformer, while in case of partial textual sequences, use composition instead.
Consider these tags and the tagging rule:
TAGS
{
@TAG1,
@TAG2,
@TAG3
}
SCOPE SENTENCE
{
TAGGER()
{
TYPE(ART)
<1:2>
@TAG1[LEMMA("product")]|[SEQUENCE]
<1:2>
LEMMA("developer")
}
}
If you apply this tagging rule to this input text:
Mark and John are the product developers.
you will get:

As you can see, the SEQUENCE transformer tagged the whole textual sequence defined in your tagging rule, even though the element to be tagged is just the lemma product.
To tag a partial and more precise textual sequence of your choice, if you have the same tags defined above but this rule with composition:
SCOPE SENTENCE
{
TAGGER()
{
TYPE(ART)
<1:2>
@TAG1[LEMMA("product")]|[#1]
<1:2>
@TAG1[LEMMA("developer")]|[#2]
}
}
applied to this text:
Mark and John are the product developers.
you will get:

As you can see, by adding the tag to the lemma developer too plus composition beside each lemma, you obtained product developers as output, without the definite article the.
Note
Using composition will tag all the tokens between the tokens affected by composition.
Tagging by script
Tagging by script allows adding and deleting tags using the onTagger and the onTaggerLevel event-handling functions.