The similarity use case
The use case
The similarity use case refers to the need, in a large document base, to find documents similar to a document of choice.
Platform allows managing this case using indexes and workflows. For this purpose, an NL Flow runtime can be equipped with Elasticsearch as the index manager.
The key concepts on which this solution is based are:
- Index all the documents in the document base and then query the index to find documents similar to a given one.
- Do not index the plain contents of the documents but rather features—metadata—that represent the documents themselves and that are obtained by submitting the text of the document to a linguistic model. It is the quantity of correspondences between the metadata values that determines how similar two indexed documents are.
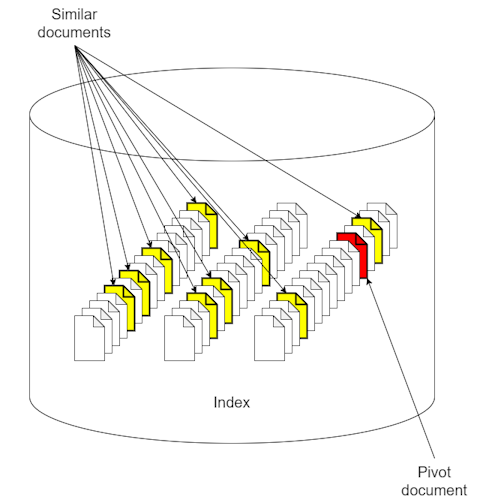
Model predictions—categories in case of categorization models, extracted and normalized information in case of extraction models, concepts of the taxonomy mentioned in the text in case of thesaurus models—are typically indexed as metadata.
In addition to this, other metadata produced by NL Core can be indexed: named entities (people, places, organizations, etc.), main concepts, main lemmas, topics of the Knowledge Graph and so on.
Workflows
Three workflows are needed to manage similarity:
- A workflow to create the index.
- A workflow to analyze and index the documents.
- A workflow to query the index and find documents similar to a given one.
The workflows use specific components, indicated below, to manage and query the Elasticsearch index and also to make the output data of the predictive model indexable.
Index management workflow
The workflow that serves to create the index gets called once for that purpose.
The workflow is simply made up of a block of the Similarity Manager component.
In addition to creating the index, this component can delete an index or list all existing indexes.
The behavior is determined by an input parameter, so with different calls the same workflow can do one of the three things at will.
Analysis and indexing workflow
The analysis and indexing workflow is used after creating the index with the first workflow and consists of a flow of three blocks:
- The predictive linguistic model.
- A pre-processor that prepares the data to be indexed, based on the Similarity Document Preparator component.
- The indexer that writes document metadata to the index, based on the Similarity Indexer component.
This workflow must be called for each document in the document base.
Which output metadata of the predictive model to index and related to which sections of the text is determined by a similarity model previously prepared within the linguistic model project, in the authoring section of Platform.
In addition to the metadata used to compare documents, it is possible to index additional metadata. This will not play a role in determining similarity, but can be returned for each similar document found with the third workflow: it is additional information on documents for any purpose.
The fundamental data of each document is its identification code. This can be known a priori, that is, be a key characteristic of the document (the name or path of the file, or something else) in the document base. This identifier must be passed to the third workflow to indicate which is the pivot document for which similar documents are to be found.
Alternatively, the document identifier can be generated by the workflow and returned in the workflow output.
In this case, it is up to the caller to store it in association with the document in the document base, always with the aim of knowing what data to pass to the third workflow when similar documents are to be found.
Query workflow
Once all documents are indexed with the second workflow, the third workflow is used to find documents similar to a given one.
The user provides the identifier of the pivot document and obtains the list of identifiers of similar documents with the possible addition of metadata to describe each result. This workflow also uses the similarity model that has been prepared in the project of the linguistic model, this time to ask the search engine to perform the comparison on chosen metadata and also to give a possible boost to the similarity score when the match concerns one metadata rather than another.
This workflow consists solely of one block of the Similarity Calculator component.
Similarity models
The similarity models that can be used in workflows 2 and 3 are managed in the Models view of the main dashboard of NL Flow GUI.